


How Teams Lose Control When They Add AI Agents to Their Stack
In most engineering teams, changes follow a predictable path. A developer updates code or configuration, opens a pull request, and runs it through tests. If the diff looks correct and checks pass, the change is merged and deployed.
This model assumes that reviewing a change at the level of a diff is enough to judge its impact. Most of the time, that assumption holds because engineers read beyond the code. They factor in dependencies, past incidents, and the parts of the system that tend to fail under load.
Even then, failures are common. Research from Google SRE shows that nearly 70% of outages are triggered by changes to live systems. These changes often look safe in review and pass every test, yet still fail once they interact with real conditions.
Now consider the same workflow when an agent introduces changes. The process remains identical, and decisions are still made from what is visible in the diff and test results. A change can pass every check and appear safe, yet still break a dependent service because its impact extends beyond what the review process captures.
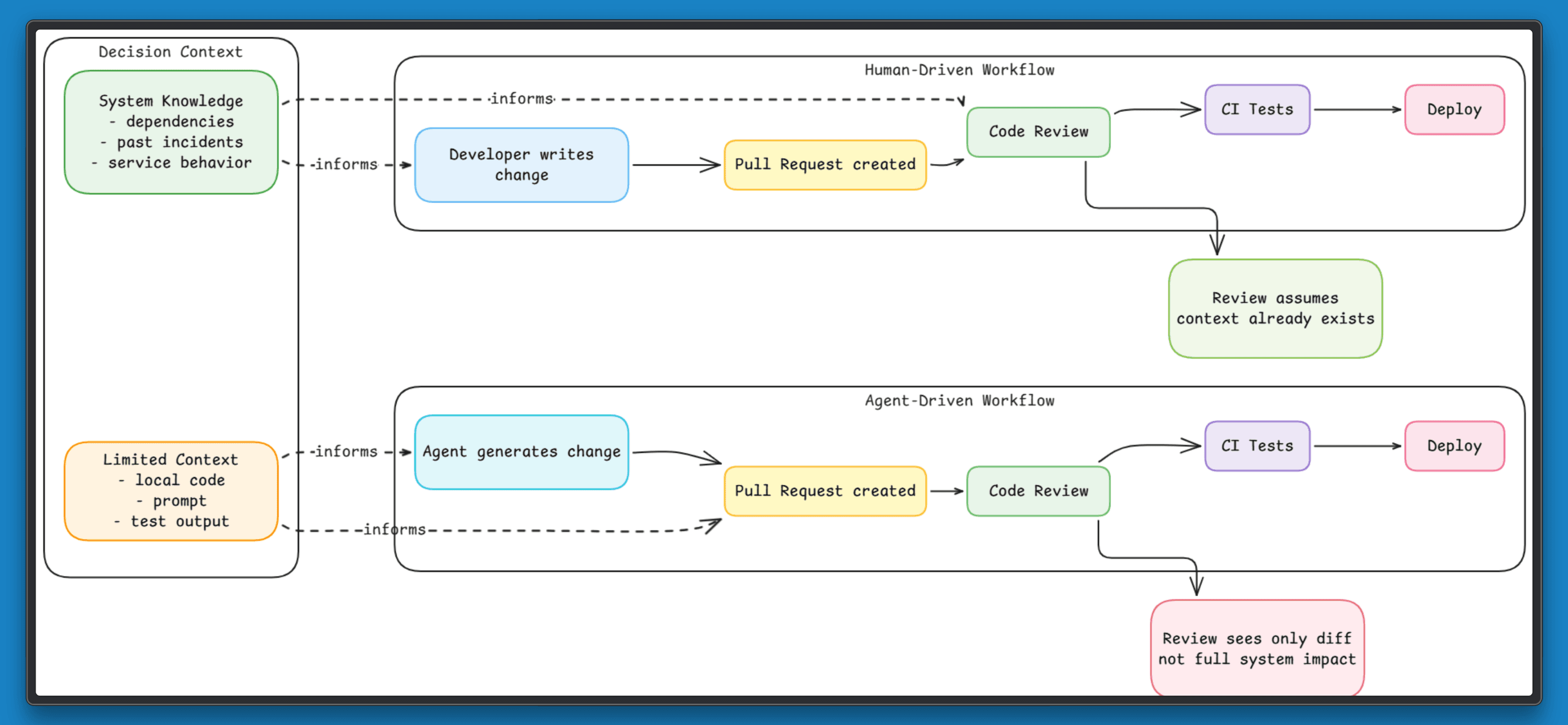
The gap is not in the code. It is in how the change is evaluated. In this article, we examine why this gap appears, where existing workflows fall short, and what needs to change to regain control.
How Clean Diffs Reduce Scrutiny
When agents generate updates, they often produce complete pull requests. The diff is clean, follows conventions, includes tests, and passes CI. It looks ready to merge.
That appearance shapes the review. Reviewers rely on signals. Messy diffs or unclear logic slow them down and trigger questions. A clean pull request does the opposite. It suggests the work has already been thought through, so it gets less scrutiny and moves faster.
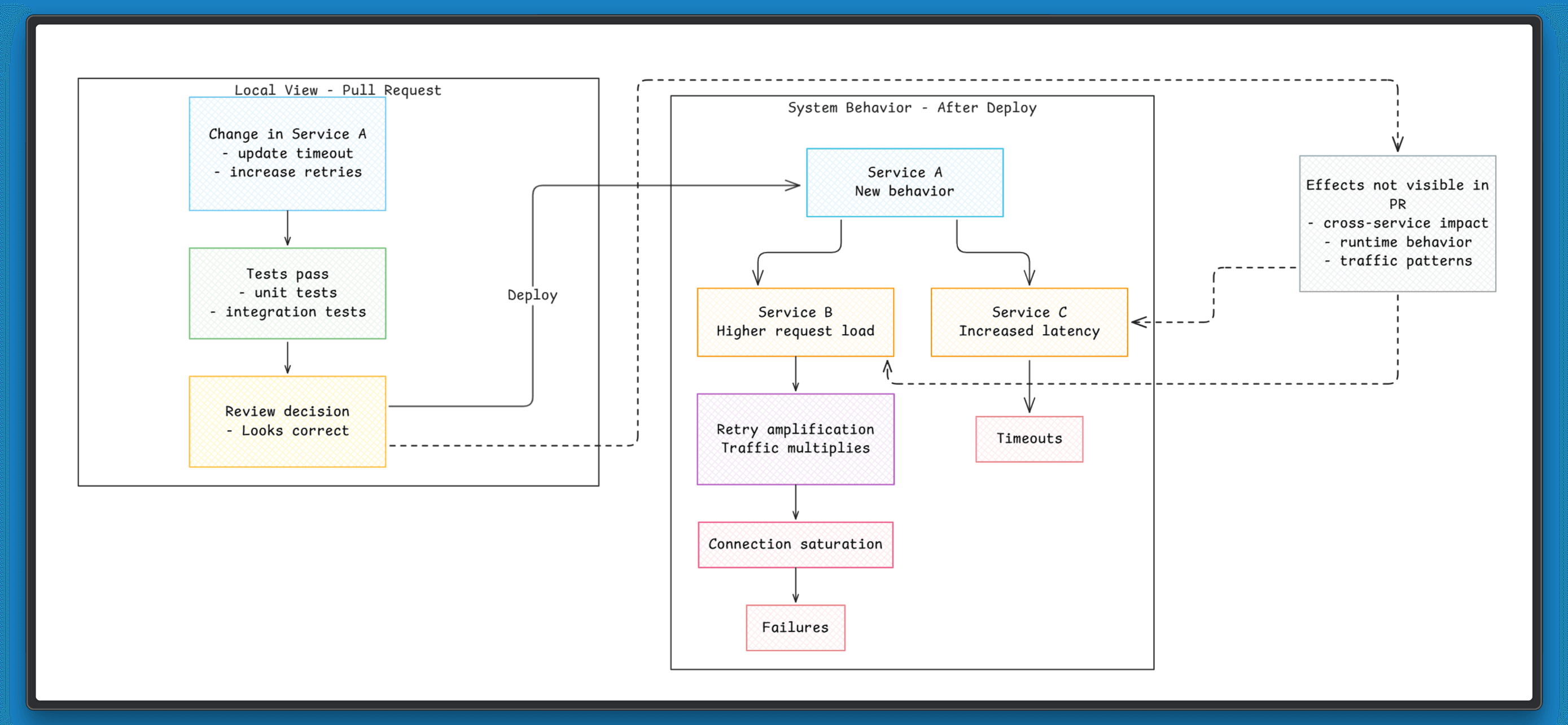
The risk does not disappear. It sits outside the diff. A configuration tweak can affect timeouts in another service. A small refactor can change how a dependency behaves under load. These effects are not visible in the pull request, so they are rarely questioned during review.
The result is simple. The cleaner the pull request looks, the less likely it is to be challenged, even when it carries hidden risk.
What Actually Goes Wrong When Agents Make Changes
Once agents start introducing changes, the failures are not in the code itself. They come from how those changes interact with the rest of the system, often in ways that are not visible during review.
These issues tend to show up in a few consistent ways.
Changes are evaluated in isolation
Agents work within a limited scope, usually a pull request or a small set of files, and build changes that are internally consistent within that boundary. Tests tied to that scope pass, which makes the change appear safe.
The system behaves differently once that change is deployed. A configuration update can increase load on a dependent service, and a small change in request handling can affect latency across a chain of calls.
Review confirms the change within its local context, but the system responds based on interactions beyond that scope. A change can be correct in isolation and still cause issues when it becomes part of the larger system.
There is no shared memory of the system
A team already knows that a particular service struggles when retries increase. In the past, even a small rise in retries caused the load to spike and led to failures, so changes around retry logic are handled carefully.
A new change increases the retry count from 2 to 5 to improve reliability. The update looks reasonable, passes tests, and moves through review.
After deployment, the service starts receiving more retry traffic than it can handle, and failures begin again. The change itself is valid. The problem is that it repeats a known issue the team had already learned to avoid.
Actions are hard to trace end-to-end
A change moves through the system as expected. A pull request is created, reviewed, merged, and deployed. Each step is visible. The difficulty comes when trying to connect them.
When a service fails after deployment, the change is easy to find. The reasoning behind it is not. It is hard to see why the change was made or what led to it, which slows down debugging and makes issues harder to understand.
Behavior is inconsistent
The same issue can lead to different fixes at different times. A small change in input or context can produce a different outcome, even when the problem looks similar.
This makes behavior harder to predict. Teams cannot rely on a consistent pattern when changes are introduced. Debugging becomes slower because there is no stable reference point. Each issue has to be understood from scratch, even if it looks like something seen before.
Decisions Are Made Without System Context
Most AI-driven changes rely on a narrow slice of information. The focus stays on the code in front of the change, along with the inputs and tests tied to that scope. Engineering systems behave very differently. They are:
Distributed across multiple services
Stateful over time
Dependent on interactions between components
This creates a gap. The decision is based on what looks correct in isolation, but the outcome depends on how that change affects other parts of the system.
For example, increasing a timeout might reduce errors in one service, but it can also hold connections longer and increase load on another. Changing retry logic can improve success rates locally, while amplifying traffic across a dependency chain. These effects are not visible at the point where the decision is made.
This leads to a pattern where local improvements introduce system-level issues. Each change makes sense on its own, yet the system becomes harder to reason about over time. You cannot safely change a system if the decision does not account for how that system behaves as a whole.
Why Existing Tooling Does Not Fix This
Teams already rely on a mature set of tools to manage code, testing, and production systems. These tools are effective within their scope, but they do not address how a change behaves across the system as a whole.
To understand the gap, it helps to look at how each layer evaluates changes:
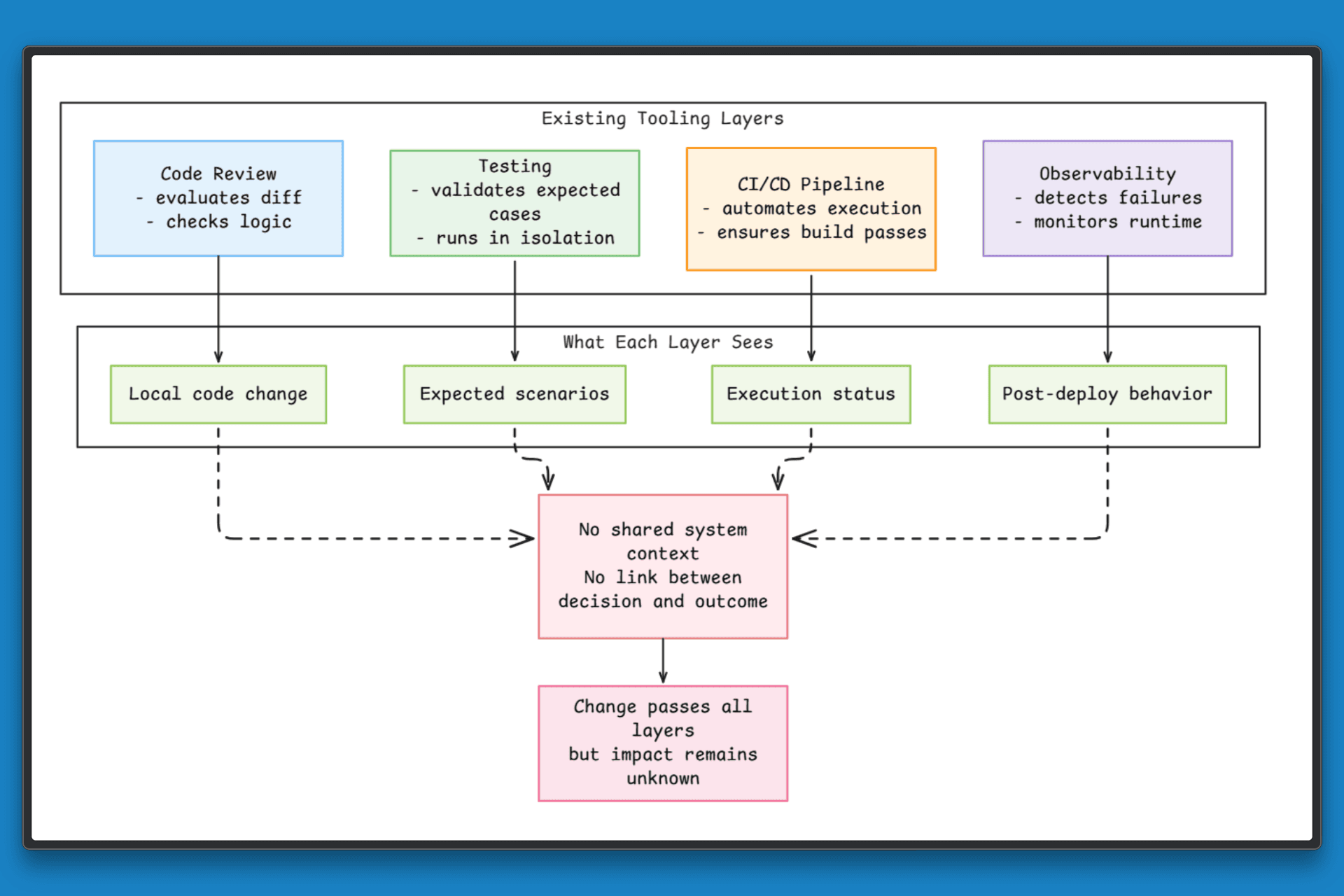
Code review focuses on the diff: It helps identify issues within the change itself, but it does not capture how that change affects other services or shared resources.
Testing frameworks validate expected cases: Known scenarios are covered, but real traffic patterns and cross-service interactions are not represented.
Observability surfaces issues after deployment: Failures and performance problems become visible, but the link back to the original decision is often unclear.
Automation and agents execute changes quickly: Speed and consistency improve, but the inputs remain limited to what is immediately available.
Each of these layers works well on its own. The gap appears because none of them connect the decision behind a change to its system-wide impact.
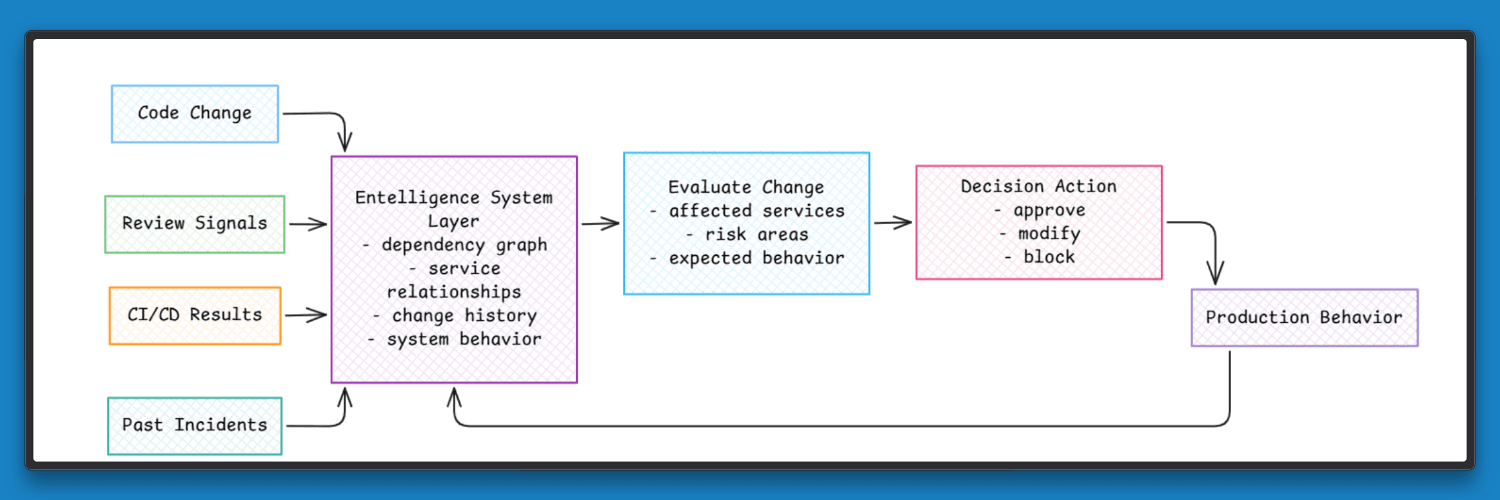
Introducing a System Layer for Engineering Context
The problem is a disconnect between how decisions are made and how the system actually behaves.
A change moves from code to review, then to deployment, and finally into production. Each step is visible on its own, but they are not tied together. Teams can see what changed and when it was deployed, but it is harder to see how that change affected other parts of the system.
A system layer connects these steps. It links code changes with reviews, test results, and what happens after deployment. It also incorporates past incidents and known problem areas, so decisions are based on how the system has behaved.
Platforms like Entelligence AI follow this approach. They build a view of how the system evolves over time and how different parts affect each other. When a new change is introduced, it can be evaluated in the context of the full system. This makes it easier to understand what a change might affect before it reaches production.
From Uncontrolled Agents to Governed Systems
When agents operate on a limited view, their behavior becomes hard to predict. The same type of change can lead to different outcomes depending on conditions that were never part of the decision.
Adding more checks does not solve this. The issue is not speed or correctness at the code level. It is that decisions are being made without enough understanding of how the system behaves. With system-level context, the nature of those decisions changes.
A change can be evaluated against how similar updates behaved in the past, how services depend on each other, and how load and traffic patterns affect different parts of the system. This brings consistency. The outcome of a change becomes easier to reason about because it is grounded in how the system actually works.
This changes the role of agents. Instead of generating suggestions and pushing them forward, they operate within a system that evaluates impact before the change proceeds.
That is the difference between uncontrolled automation and governed systems. The system provides the context, and the decisions follow from it.
What Changes Once This Layer Is in Place
The workflow stays the same, but the way decisions are made and validated improves across the system.
Review includes system context: Changes are seen alongside past updates, related services, and known risk areas, which helps surface issues earlier.
Debugging becomes easier to follow: The path from change to impact is clearer, so teams can trace what happened and why without piecing together multiple tools.
Patterns become visible over time: Teams can identify sensitive parts of the system, understand which changes lead to issues, and see how problems spread.
Decisions become more consistent: Changes are evaluated against system behavior and past outcomes.
System understanding improves across teams: Entelligence AI connects code changes with production behavior and incidents, giving teams a shared view of how the system evolves.
Automation becomes more reliable: Changes are evaluated in context before proceeding, leading to more predictable outcomes.
Closing
Software systems have always been complex, yet they have once changed at a pace where human judgment could keep up. That pace has increased.
Agents now introduce and apply changes at a pace that exceeds what manual review alone can handle. Each change may look correct, yet its effect depends on how it interacts with the rest of the system. The next step focuses on building systems that understand these interactions. Entelligence AI follows this approach by connecting changes with real system behavior over time.
The question ahead is simple: as change becomes faster, how do teams keep their systems understandable?