


Your Code Reviewer Can See Everything. And Yet, Production Keeps Breaking
Introduction
In teams that adopted AI coding tools, PR volume went up nearly 98%, and production incidents went up 23.5% in the same period. Those two numbers should not be moving in the same direction, and yet here we are.
The obvious explanation is code quality. AI-generated code does introduce more issues than human-written code, and that is a real problem worth solving. But code quality alone does not explain why the review layer, the thing specifically built to catch those problems before they ship, keeps missing them.
The review tooling got better, too; most AI reviewers today can read your entire codebase, understand cross-file dependencies, and flag issues in seconds, but incidents are still climbing. Which means the problem is not in how much the reviewer can see. It is what the reviewer has never been taught to remember.
What Actually Changed When AI Entered the Workflow
To understand why incidents are increasing, it's useful to see what changed when AI coding tools became common in the workflow
The tools delivered on their promise in a real way. Writing boilerplate got faster, first drafts of features took less time, and teams started shipping more code without adding headcount. For engineering leads trying to move faster without growing the team, this felt like exactly what they needed, and for a while, it looked like it was working.
But something changed quietly underneath all of that. As AI started writing more of the code, the number of PRs entering the review queue grew faster than anyone had fully planned for. More code meant more changes, more changes meant more PRs, and more PRs meant teams needed a way to review all of it without slowing down. That is when teams started leaning on AI review agents, tools like CodeRabbit, Augment Code, and Greptile.
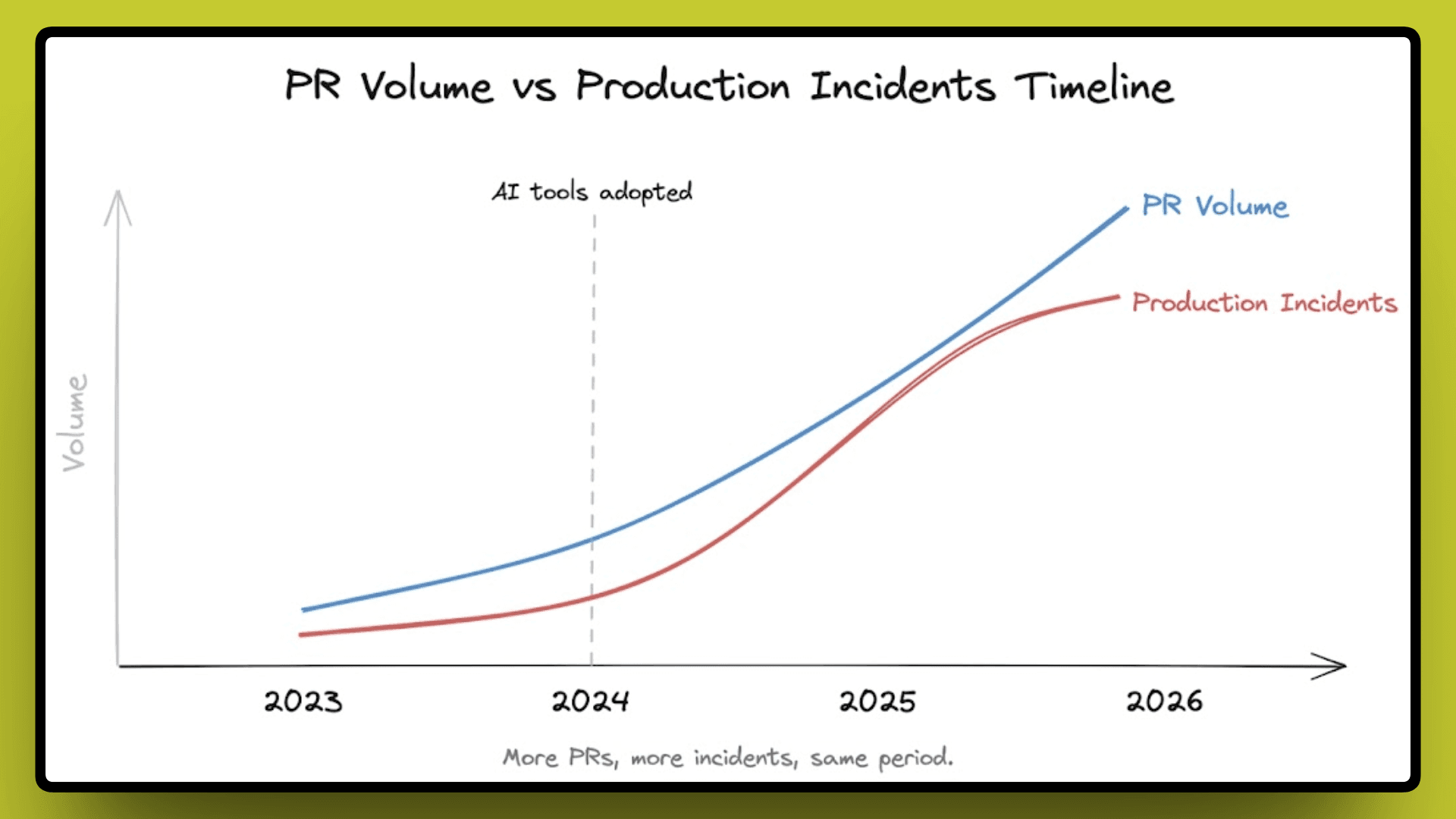
The assumption teams made was simple enough: if AI can write code faster, AI can review it faster too, and the quality will hold. But that assumption had a gap in it that only showed up later in production numbers.
PR volume went up, but the quality of reviews did not move with it. More PRs were getting reviewed, just not reviewed well, and that is where the problem started showing up in production.
The Review Quality Problem Nobody Is Talking About
The conversation around AI review quality almost always lands on context. Does the tool read the full codebase? Does it understand the surrounding files? These are fair questions, but they are aimed at the wrong problem.
When a senior engineer reviews a PR, they are not just reading the code. They remember that this exact pattern caused a connection timeout three months ago, and that this service has had two incidents in this area already. That memory is what makes the review valuable, and it is not something you get from reading files.
Here is where it gets worse. Teams using AI tools are now merging 98% more PRs than before, which means senior engineers are reviewing more code per day with less time per PR. The memory is still there, it just gets rushed.
AI reviewers have a different problem. They were never present when anything broke. No record of the 2 am incident, no signal from any post-mortem. And the numbers show it: AI-reviewed code still produces 1.7x more issues than human-reviewed code, and change failure rates across AI-heavy teams are up 30%.
These tools know your codebase, but they do not know your history, and giving a reviewer more context does not solve that, because the problem was never about how much it could see.
Why "More Context" Doesn't Fix This
The industry saw the quality gap and tried to close it. Full codebase access instead of just the diff, history from past PRs, surrounding files, and linked tickets. And to be fair, it helped with a specific class of problems. Cross-file logic errors, broken imports, mismatched types across modules, these became easier to catch when the tool could see the whole picture.
But the incidents kept climbing anyway, and that is the part worth sitting with.
Reading more code tells you what the codebase looks like right now, but it does not tell you what the codebase has already done in production. No file in your repository contains the information that a specific API pattern caused a cascade failure six weeks ago, or that a particular database query quietly exhausted the connection pool under load, or that the last time someone touched this service it took three engineers two days to recover. That knowledge exists, but it's scattered in Slack threads, post-mortems, and the minds of the engineers who were on-call at the time.
Context and memory are two different things:
Context is what you can see.
Memory is what you learned from what broke.
Tools that added more context got better at the visibility problem, but the memory problem stayed exactly where it was.
What Production Memory in a Reviewer Actually Looks Like
So what would it actually mean to close the memory gap instead of the visibility gap?
It would mean a reviewer who does not just read your code but knows what your code has already done in production. Not in a general sense, but specifically: this function, this service, this pattern, and what it cost the last time someone shipped something similar. That is a different kind of knowledge entirely, and it does not come from reading more files, it comes from watching what happens after the code ships.
The practical difference is huge. A reviewer with production memory does not just see a function that could cause a timeout, it knows that a structurally similar function caused a timeout in this codebase six weeks ago, what alert fired, how long it took to resolve, and that the team spent half a sprint cleaning it up. That is not a pattern match, that is institutional knowledge built from real outcomes.
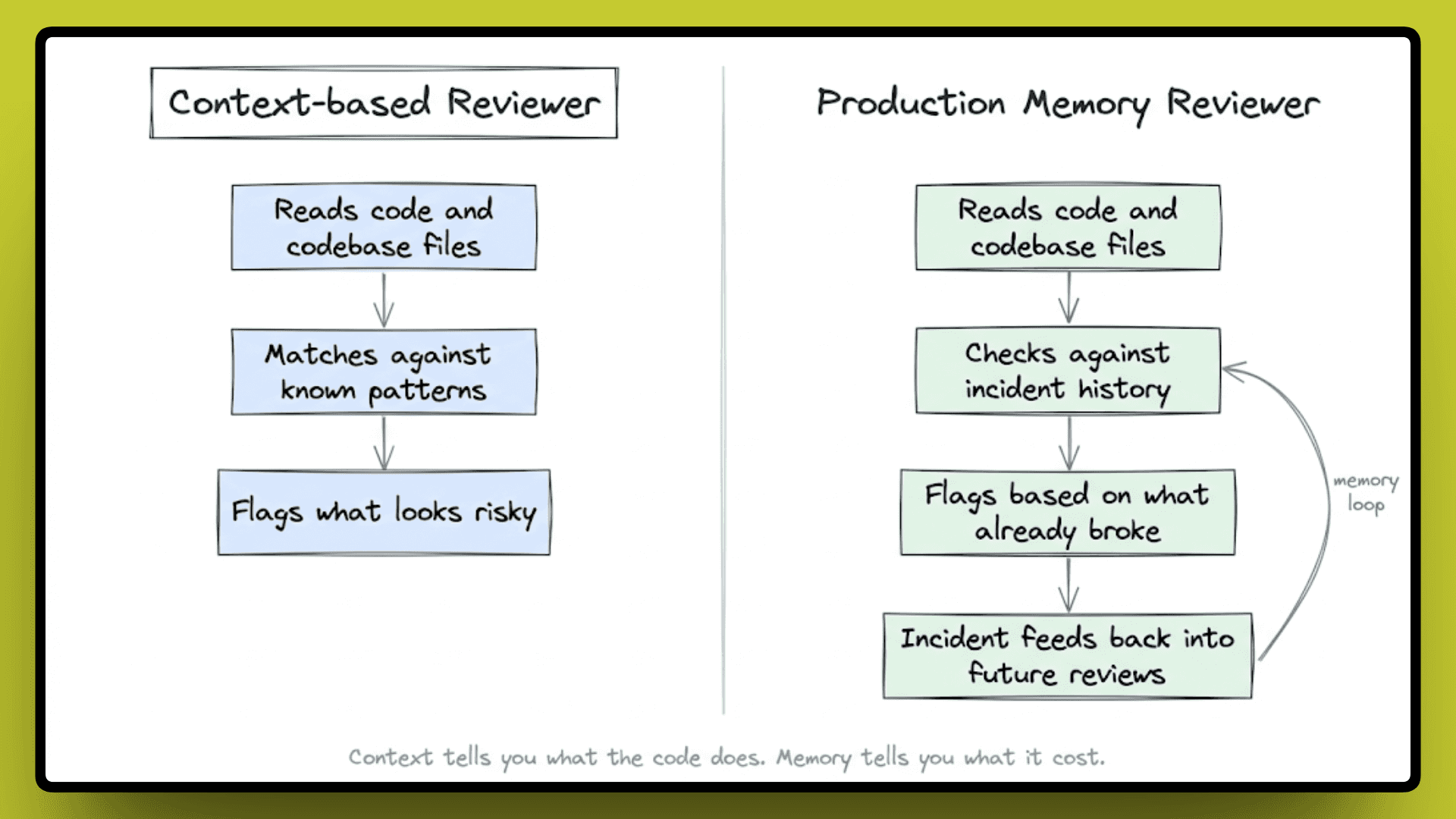
This is the architecture Entelligence works from. Every pull request is tracked, production is monitored after code is released, and any failure informs future code reviews. The reviewer doesn't just recognize patterns; they remember the impact for future reviews. It's more like an engineer who experienced the issue firsthand and remembers it.
To measure whether that actually changes outcomes, Entelligence ran a benchmark across 8 AI code review tools on 67 real bugs pulled from 5 production codebases, including Cal.com, Sentry, Discourse, Keycloak, and Grafana. In this benchmark, the examples include race conditions, security vulnerabilities, breaking API changes, and logic errors that had already caused real damage in production.
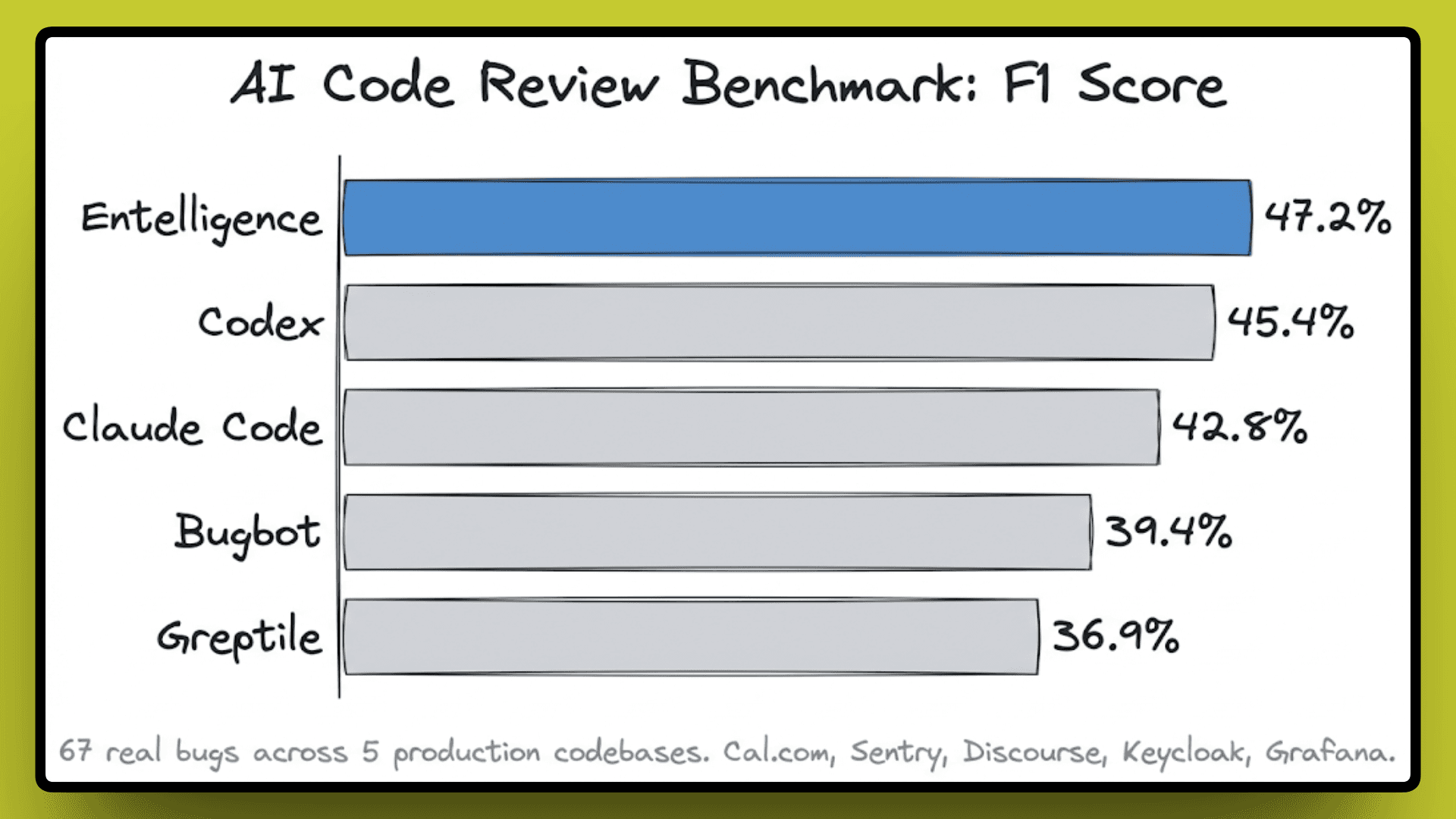
Entelligence came in first with a 47.2% F1 score. To understand why that number matters, the F1 score balances precision and recall together.
High recall with low precision means the tool flags everything, and your developers learn to ignore it.
High precision with low recall means it only comments when it is confident, but misses a lot.
A strong F1 means the tool is both catching real bugs and not drowning the team in noise, which is the actual problem most teams face with AI reviewers today.
In a real deployment, Sybill used Entelligence across 187 PRs over 8 weeks. No critical issues reached production, 5 production-level bugs were caught before deploy, the median PR turnaround dropped from 5 hours 12 minutes to 1 hour 47 minutes, and the team saved roughly 350 engineering hours. The developer approval rating on review comments was 73%, which in practical terms means engineers found the feedback useful enough to act on rather than dismiss.
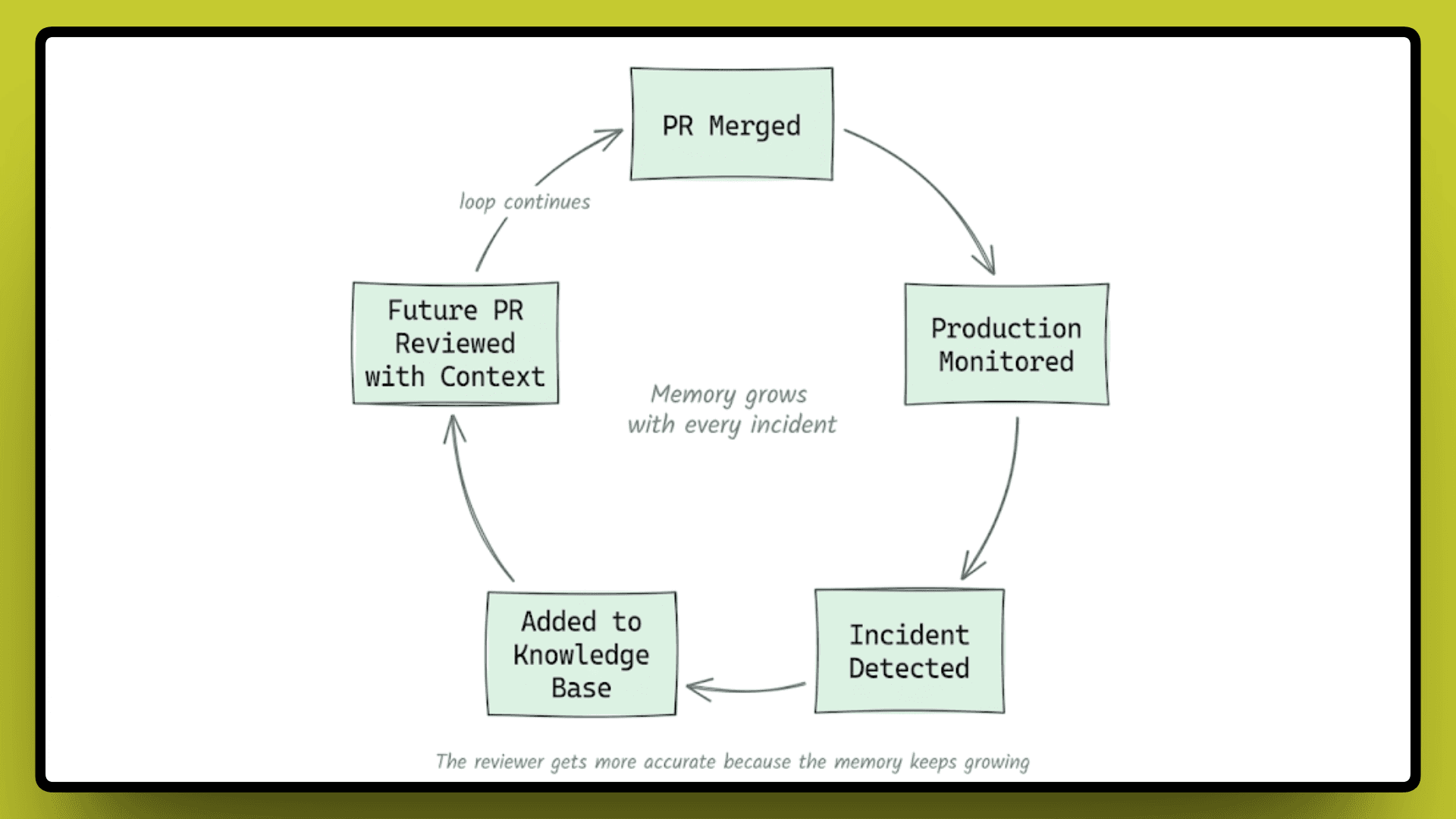
The reviewer gets more accurate over time, not because the model improved, but because the memory of what this specific codebase has already cost keeps growing with every incident.
What This Means for Engineering Teams Practically
The memory gap has a real cost, and it compounds every time the same class of bug reaches production twice. The IBM Systems Sciences Institute reported that a bug caught during development costs around $100 to fix. The same bug caught in production costs $10,000, and that is before factoring in downtime, customer impact, and the engineering hours spent in the post-mortem. Development teams already spend 30 to 50% of their time fixing bugs and dealing with unplanned rework, and a reviewer with no memory of past failures keeps feeding that cycle.
The practical question for engineering leads is not which review tool has the best benchmark score. It is whether the review layer is actually learning from what your codebase has already done, or whether every PR is being reviewed as if none of your past incidents ever happened.
Teams that close the memory gap stop paying the same cost twice. They stop writing the same post-mortem for the third time, stop patching the same class of bug in the same service, and stop pulling senior engineers from planned work to handle issues that a better-informed review could have caught earlier.
The question worth bringing back to your team is a direct one: Does your reviewer know what broke last quarter, and if not, where is that knowledge going?
Closing
The question at the end of all of this is not which tool has the best benchmark or the fastest review time. It is whether the review layer in your team is actually getting smarter over time, or whether it is starting from zero every time a new PR comes in.
Speed compounds in one direction, and so does memory. Teams that build a reviewer with real production memory behind it will not just see fewer incidents, but they will stop losing engineering hours to the same problems over and over, and that is where the real cost of bad reviews lives.
Reviewing faster was never the hard part. Remembering what already broke is.
References:
Cortex Engineering Benchmarks 2026, Cortex
Code Review Benchmark 2026, Entelligence
Entelligence Case Studies, Entelligence
IBM Systems Sciences Institute, Relative Cost of Fixing Defects, ResearchGate
On the credibility of the IBM defect cost claim, Hacker News