


What Self-Healing Code Actually Looks Like in Production
Production issues rarely start where you expect. A small change goes live, and soon after, something else fails. A service slows down, a job gets stuck, or data looks off. Nothing in the diff looks wrong, but something in the system clearly is.
When this happens, alerts start firing. Someone checks dashboards and logs to figure it out. A restart or rollback buys time. Things settle, but the real cause stays unclear, and the issue often returns.
Take a simple case. A service fails when a dependency times out under load. The fix is known. Restart it, clear the connection pool, and it recovers. The next time, the same steps repeat. The system does not remember the fix.
This is the gap behind self-healing systems. It relies on spotting the pattern and applying the same fix safely, without someone having to step in each time.
For this to work, the system needs a way to store fixes, apply them consistently, and ensure they run safely in production. That’s the direction Entelligence is built around. It turns repeated failure patterns into controlled fixes that can run safely in production.
In this article, we look at self-healing code in production and the role of control and system awareness in ensuring reliable operation.
How Self-Healing Works in Real Systems
Self-healing starts when a system can recognize a failure it has seen before and act on it with confidence. That only works if the signals are clear and tied to something real, so metrics, logs, and error rates come together to point to a specific condition.
Consider an API service under peak traffic. As load increases, response times rise, connections stay open longer, and requests begin to queue, gradually leading to connection pool exhaustion. The fix is already known. Reset the pool and restart the service, applied at the point when these signals appear together.
The same idea carries over to job systems. A slowdown in one worker spreads across the system, jobs take longer, retries increase, and the queue builds up over time. Recovery follows a similar pattern, slowing the intake of new jobs, clearing the backlog, and bringing the worker back to a stable state before resuming normal flow.
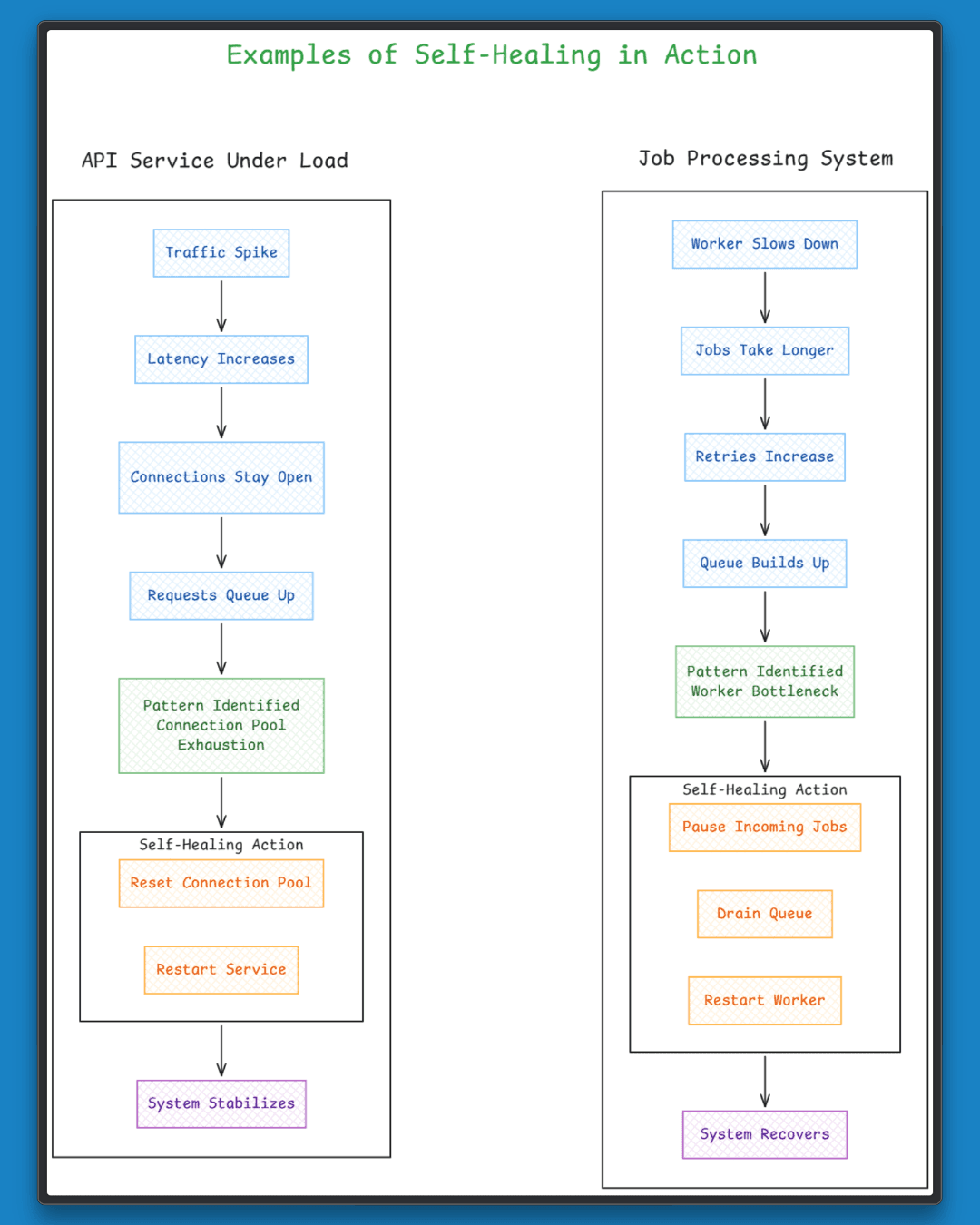
This is self-healing. The system recognizes a known pattern and applies a fix that has worked before.
The value comes from consistently linking signals to actions. Once that link is clear, the system can handle these failures on its own, without repeating the same manual steps each time.
Why the Same Production Issues Keep Coming Back
Most systems rely on restarts, retries, and rollbacks to stay up. These actions restore service, but they don’t capture anything about the failure itself.
When a service hits connection limits under load, a restart clears active connections and traffic resumes. The pattern that led to the failure, rising connections, queue buildup, and increasing latency, is not used to drive the next response. When the same signals appear again, the system treats it as a new incident.
The same holds for job systems. A slow worker leads to retries and a growing backlog. Restarting helps for a while, but the response depends on someone stepping in again and repeating the same steps.
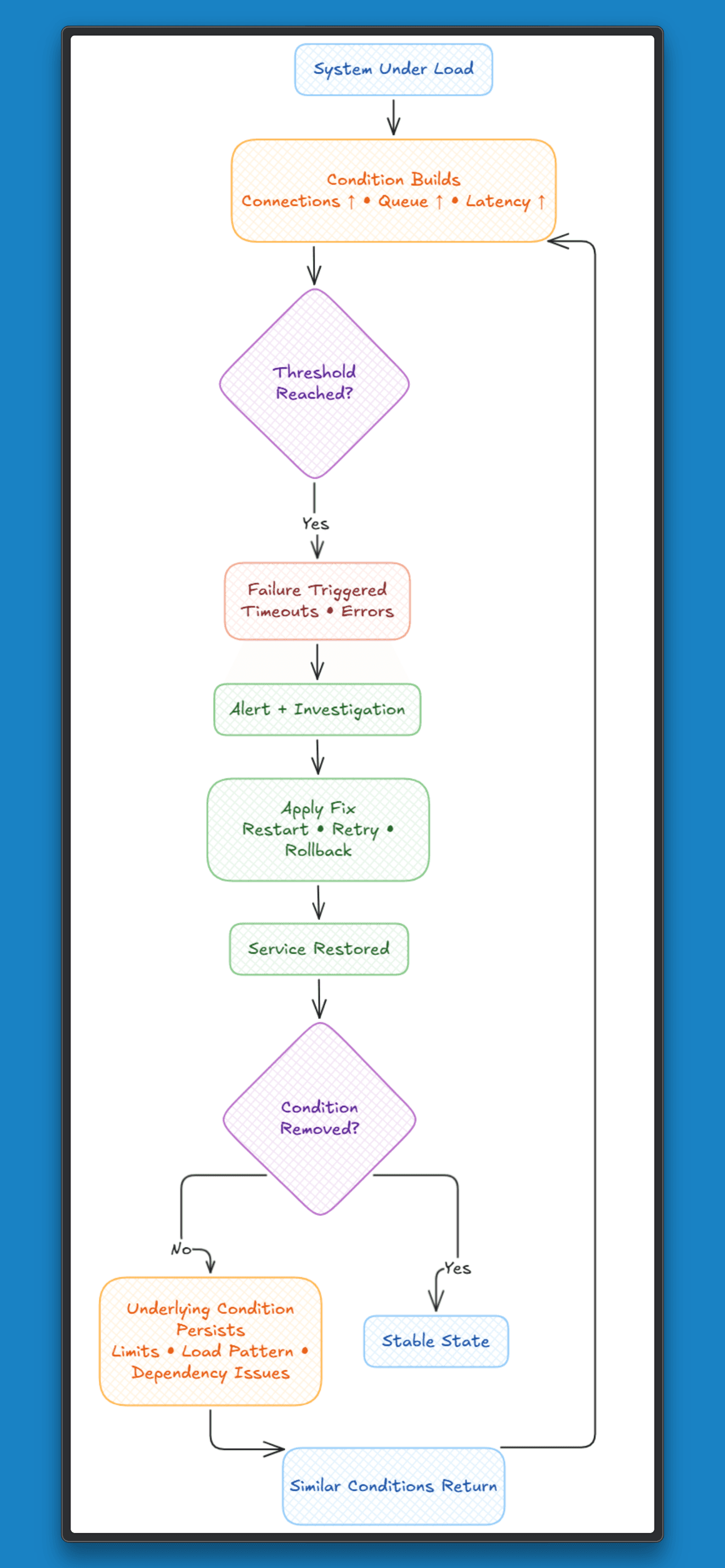
Across these cases:
The response is reactive and short-lived.
The same sequence of actions is repeated manually.
The system does not change its behaviour after recovery.
The system restores service, but it does not build a connection between cause, pattern, and action. The same signals return under similar conditions, and the same failures follow.
Why Auto Fix Breaks in Production
The common idea behind auto-fix systems
Detect a failure: Identify issues from logs, metrics, or error spikes
Generate a fix: Propose a change that seems to resolve the issue
Apply it automatically: Execute that change in the system
This flow looks simple, but it breaks down at execution.
A fix that looks correct in isolation can behave very differently in a running system. A config change might ease pressure in one service and push another over its limits. A restart at the wrong moment can drop active requests or interrupt ongoing work. A logic change can pass tests and still create data issues under real traffic.
Production systems carry state, dependencies, and timing constraints. Services depend on one another, data changes over time, and actions need to occur in the right order. Any fix interacts with all of this and must account for load, downstream impact, and sequence.
Auto-generated fixes struggle here. They are not tied to known conditions and do not follow defined execution paths. Each fix runs as a new attempt, with no guarantee that it fits the system state.
Each attempt has a cost. A fix that is slightly off can increase load or spread failure. The challenge is not detecting the issue. It is applying a change in a safe and controlled way.
What Makes Self-Healing Work
Self-healing works when failures are treated as known patterns rather than one-off incidents.
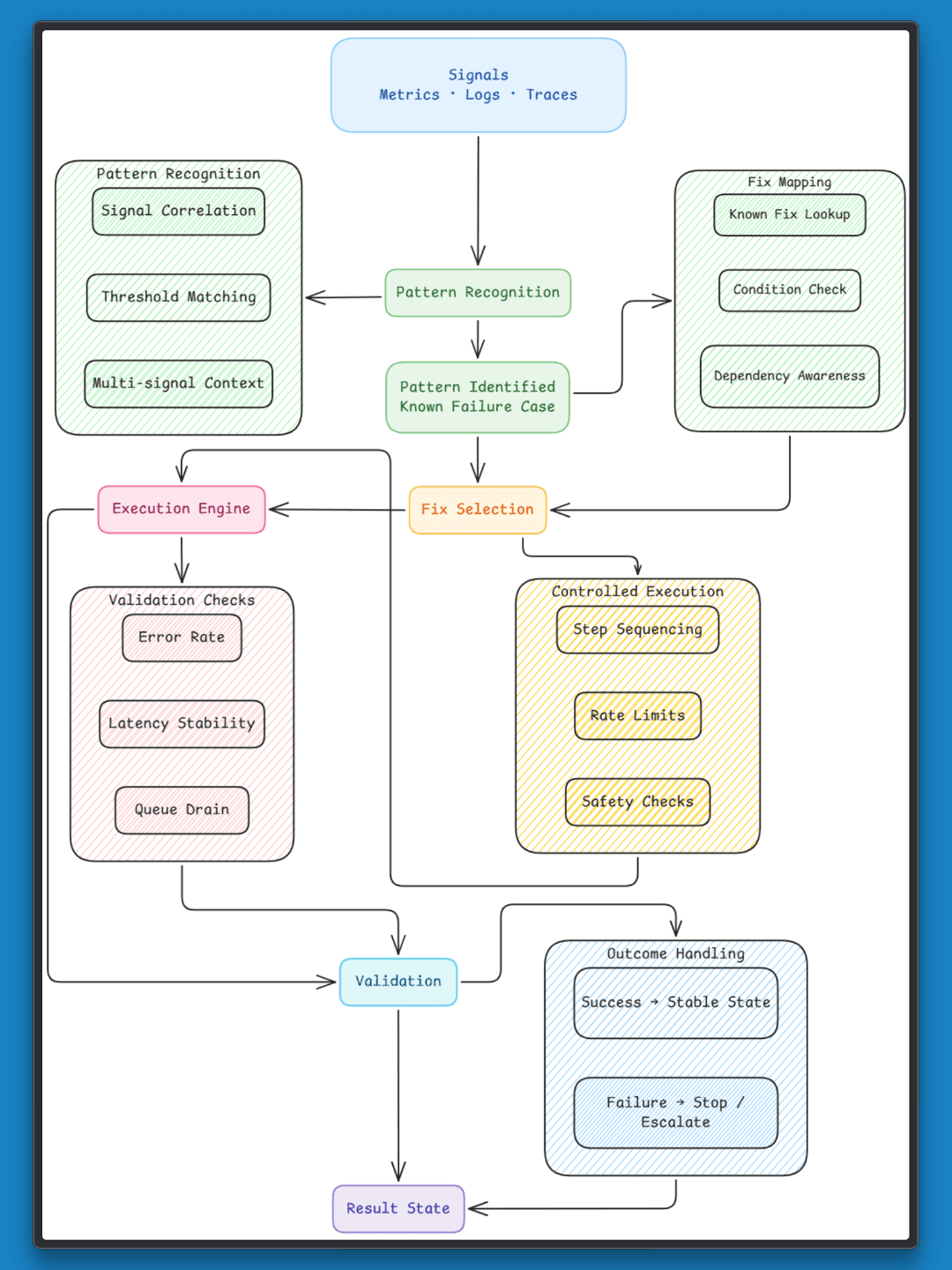
Clear signals: Metrics, logs, and traces need to converge to point to a specific condition. A spike in errors alone is not enough, but when it appears along with rising latency and queue buildup, it becomes a pattern the system can act on.
Pattern to fix mapping: Each pattern should link to a known fix. These fixes are defined in advance, tested, and tied to specific conditions. For example, connection pool exhaustion maps to resetting the pool and restarting the service under controlled conditions.
Controlled execution: Every fix needs boundaries. When it should run, how often, and under what conditions. Running a restart during peak traffic or repeating it too often can increase instability.
Validation: After a fix runs, the system needs to check if it worked. This can include monitoring error rates, latency, or queue size. If the condition does not improve, the system should stop and avoid repeating the same action.
Self-healing works when these pieces connect. Signals form patterns, patterns link to fixes, and fixes run in a controlled way with clear feedback.
The Missing Layer: Controlled Execution
Most production systems already have two pieces in place. They detect failures through alerts and metrics and run actions via scripts, jobs, or playbooks. The gap sits between these two.
Detection surfaces signals. Execution runs actions. The connection between a specific pattern and the right action, applied under the right conditions, is often missing.
A restart script exists for a service and clears connections when things stall. Timing and system state still need to be evaluated before running it. A runbook outlines the steps to drain a queue, and an engineer reads the situation, decides the moment, and executes them. The knowledge exists, though it lives outside the system.
This layer brings that knowledge into the system:
A failure pattern defined by a combination of signals
A mapped action with clear steps and order
Limits on when and how often it can run
Checks before and after execution
This creates a direct path from detection to action. The system links signals to the right response, applies it under controlled conditions, and verifies the outcome.
Where Entelligence Fits
Engineering teams already have signals, tools, and fixes. Alerts highlight issues, scripts handle recovery, and runbooks describe common failure paths. The gap shows up in connecting all of this into a system that can act with context.
Entelligence sits on top of the existing engineering stack, across code, pull requests, CI/CD, and incidents, and builds a unified view of how systems behave. It brings together code context, past incidents, and team-level patterns, so failures are understood as part of a larger system rather than isolated events.
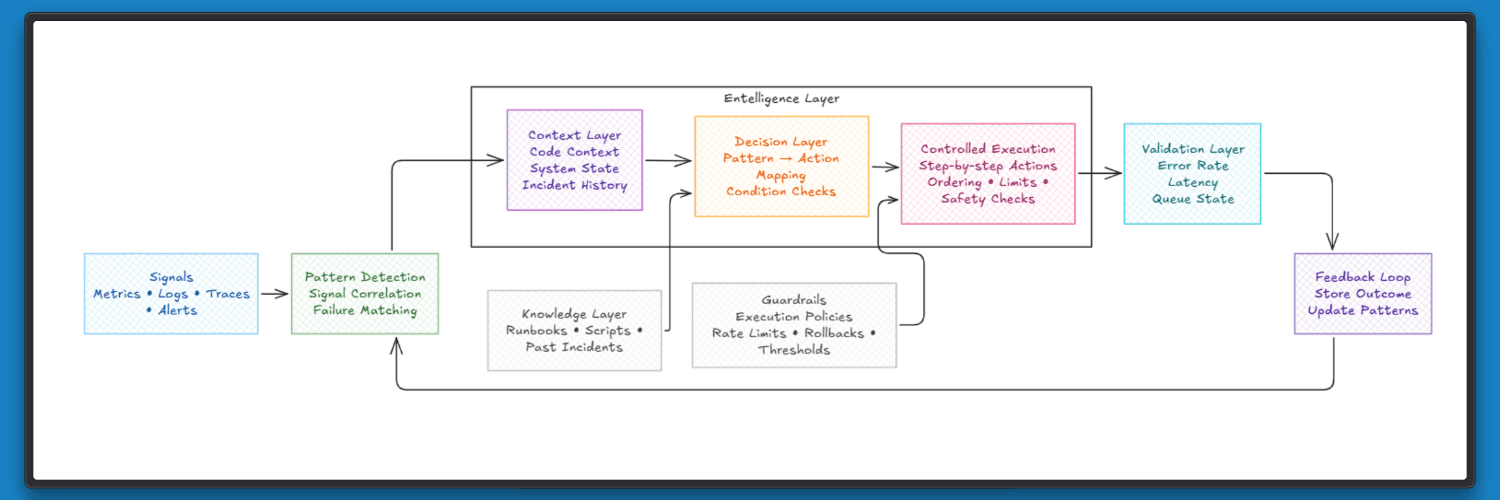
From there, it connects those patterns to actions teams already rely on. Fixes are grounded in real system behaviour, shaped by past outcomes, and applied with awareness of dependencies, timing, and impact.
This adds a layer that most systems lack. Detection and execution already exist, but they operate separately. Entelligence links them through context, turning signals into informed actions that reflect how the system has behaved before.
Over time, this means fewer repeated incidents, clearer responses, and a system that builds on its own history rather than starting fresh each time.
Closing Thoughts
Self-healing comes down to a change in how systems respond. Each failure maps to a known case with a defined response tied to real signals. The focus shifts from ad-hoc handling to consistent execution under clear conditions.
Entelligence brings this into production by turning operational knowledge into actions that the system can run on its own. Patterns engineers already understand the link to fixes with clear steps, ordering, limits, and checks.
This leads to a steadier way of operating. Failures follow a consistent path, actions are context-dependent, and each outcome is verified. Systems respond with intent, and each case builds on what already works.