Deepseek vs Claude PR Reviews
TL;DR
Deepseek R1 -
Team Claude
While building out Entelligence's PR review bot, we've tried, tested and run continuous evaluations across all models. In our previous testing across GPT-4, Claude Sonnet, and Gemini Flash, Claude has consistently emerged as the clear winner - identifying thorny edge cases and producing the fewest incorrect reviews.
Even when we asked the models themselves to evaluate each other's code reviews, every model agreed that Claude was superior at identifying critical errors and issues in the code. While GPT-4 and Gemini were able to catch several of the surface level issues, only Claude was the one able to find the more critical reasoning related issues.
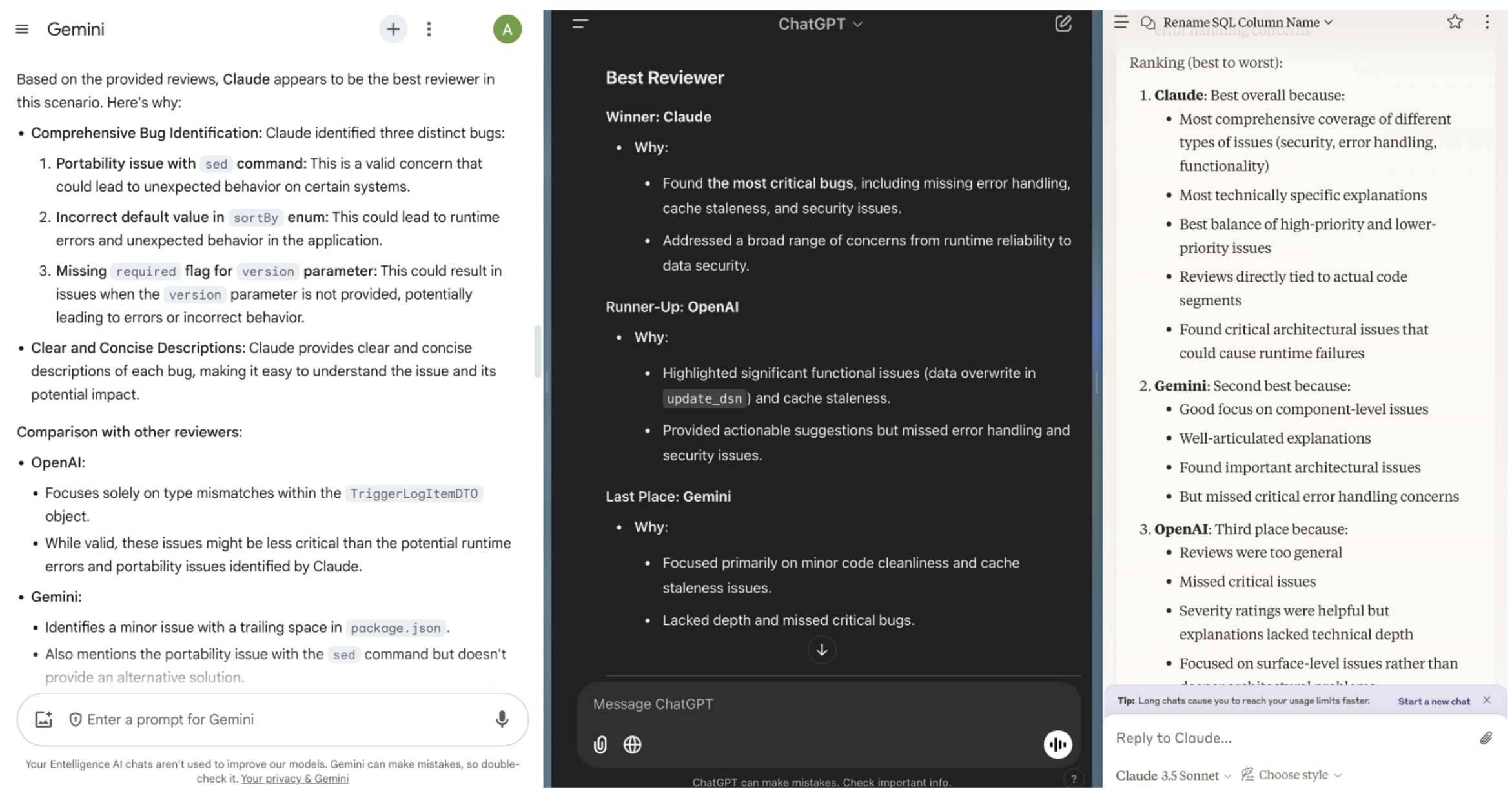
We consistently noticed that every model would confirm that the PR review comments generated by Claude were the best. Deepseek R1 seemed poised to change the game so we put it to the test against our top performer - Claude 3.5 Sonnet.
Evaluating Deepseek
Using our open source PR review evaluation framework (check out this link for reference - https://www.entelligence.ai/post/pr_review.html), we ran both models against our dataset of 500 pull requests. Given Claude's track record of outperforming other models in coding tasks, we expected similar results.
To ensure consistent classification of code review comments, we used our LLM-based evaluation system focused on functional and security issues. Here's our approach:
Analysis Prompt
You are a senior staff engineer - analyze these code review comments and categorize each one into exactly ONE of:
- CRITICAL_BUG: Comments identifying serious issues that could cause crashes, data loss, security vulnerabilities, etc.
- NITPICK: Minor suggestions about style, formatting, variable names, or trivial changes that don't affect functionality
- OTHER: Everything else - general suggestions, questions, or feedback that don't fit the above.
Respond with a JSON array where each object has:
{
"comment_index": "",
"Comment": ,
"category": "CRITICAL_BUG|NITPICK|OTHER",
"reasoning": "Brief explanation of why this category was chosen"
}
IMPORTANT: Each comment MUST be categorized. The category field MUST be exactly one of CRITICAL_BUG, NITPICK, or OTHER.
Remember: Only report issues that could actually break functionality or corrupt data at runtime.
For each PR comment, we captured the comment text, related code, and developer response. This structured approach helped maintain consistency and focus on functional impact rather than style. We've open-sourced these evaluation criteria to help standardize industry practices.

Deepseek
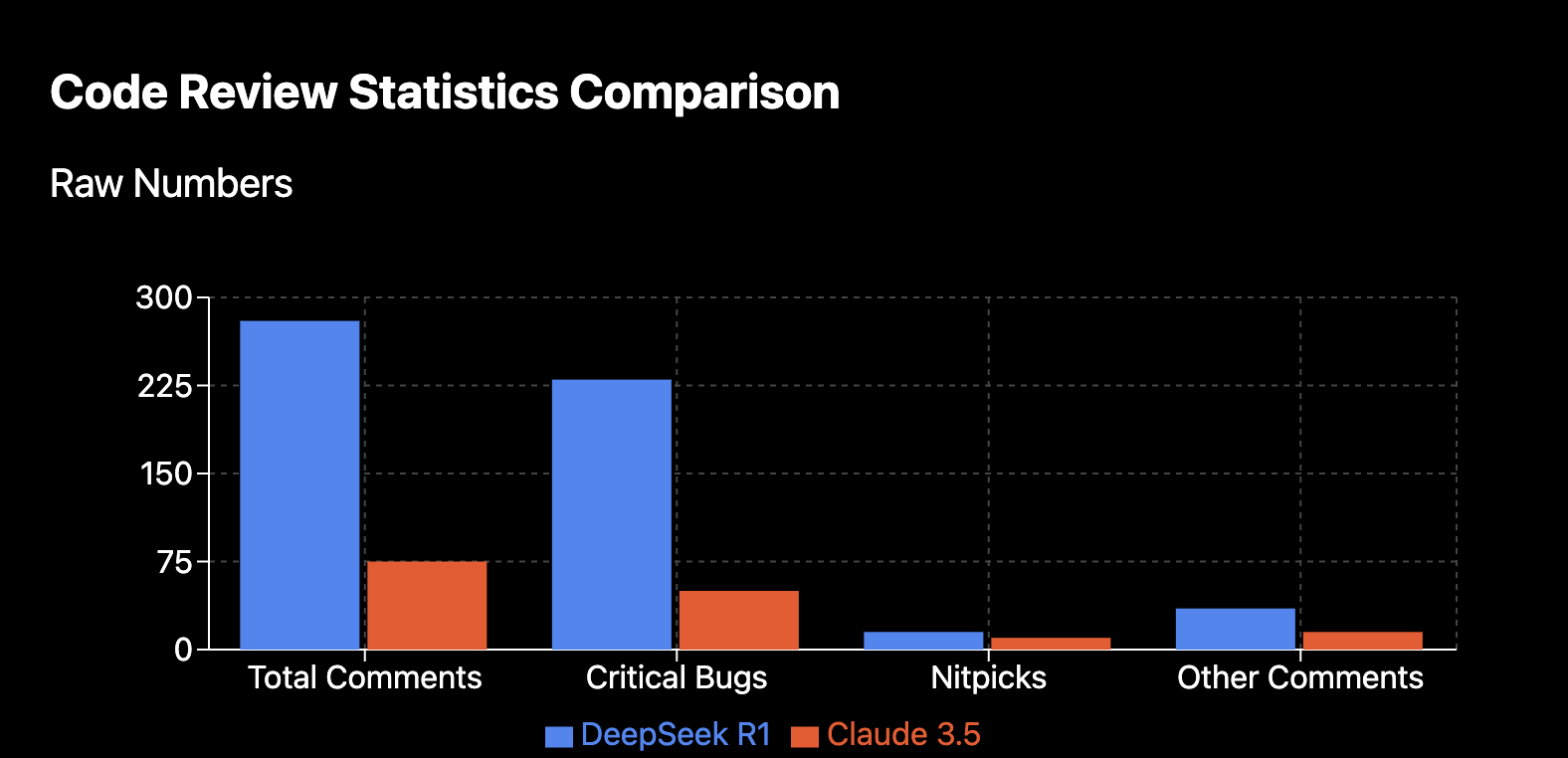
Deepseek entirely blew Claude's results out of the water with over 80% critical bug to noise ratio compared to Claude's 67%. Even more impressive than this one stat however is that Deepseek also caught 3.7x as many bugs as Claude did. I couldn't believe these stats at first so we decided to dive in deeper - here are examples of exactly how Deepseek R1 was beating out Claude PR comment by PR comment.
PR 1454: Cache and Message Repository Changes
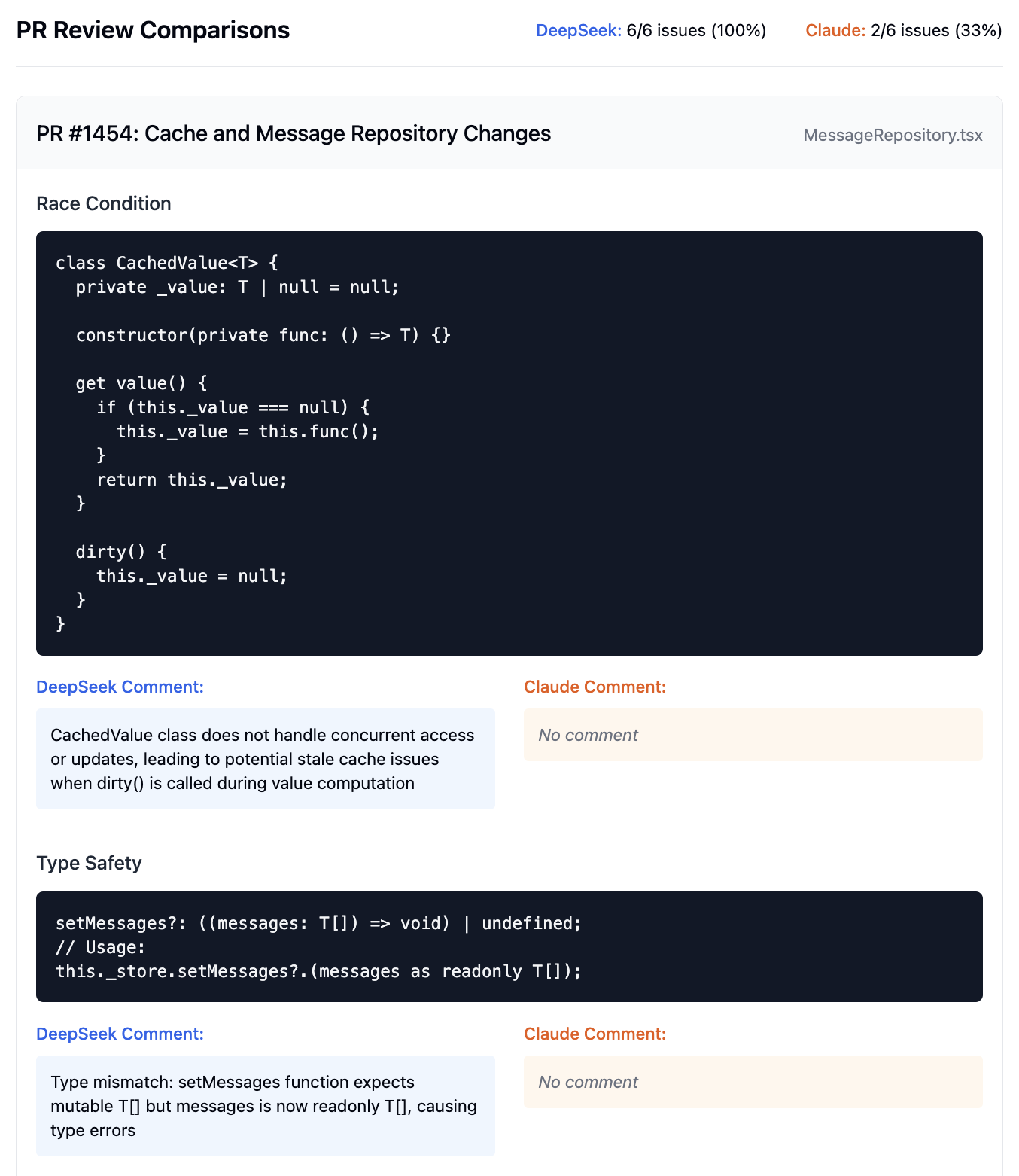
- ✅ Identified critical race condition in CachedValue class due to concurrent access between dirty() and value getter
- ✅ Caught type mismatch between setMessages function (expecting T[]) and readonly array input (readonly T[])
- ✅ Detected unsafe casting bypassing readonly constraints in ThreadMessage[] conversion
- ❌ Missed the race condition issue
- ❌ Did not identify the type mismatch problem
- ⚠️ Made generic suggestion to "add type safety checks" without identifying specific readonly constraint issues
Claude seemed unable to understanding concurrent code execution risks, catch subtle type system violations or identify specific type constraint bypasses
PR 1428: Runtime and Memory Management
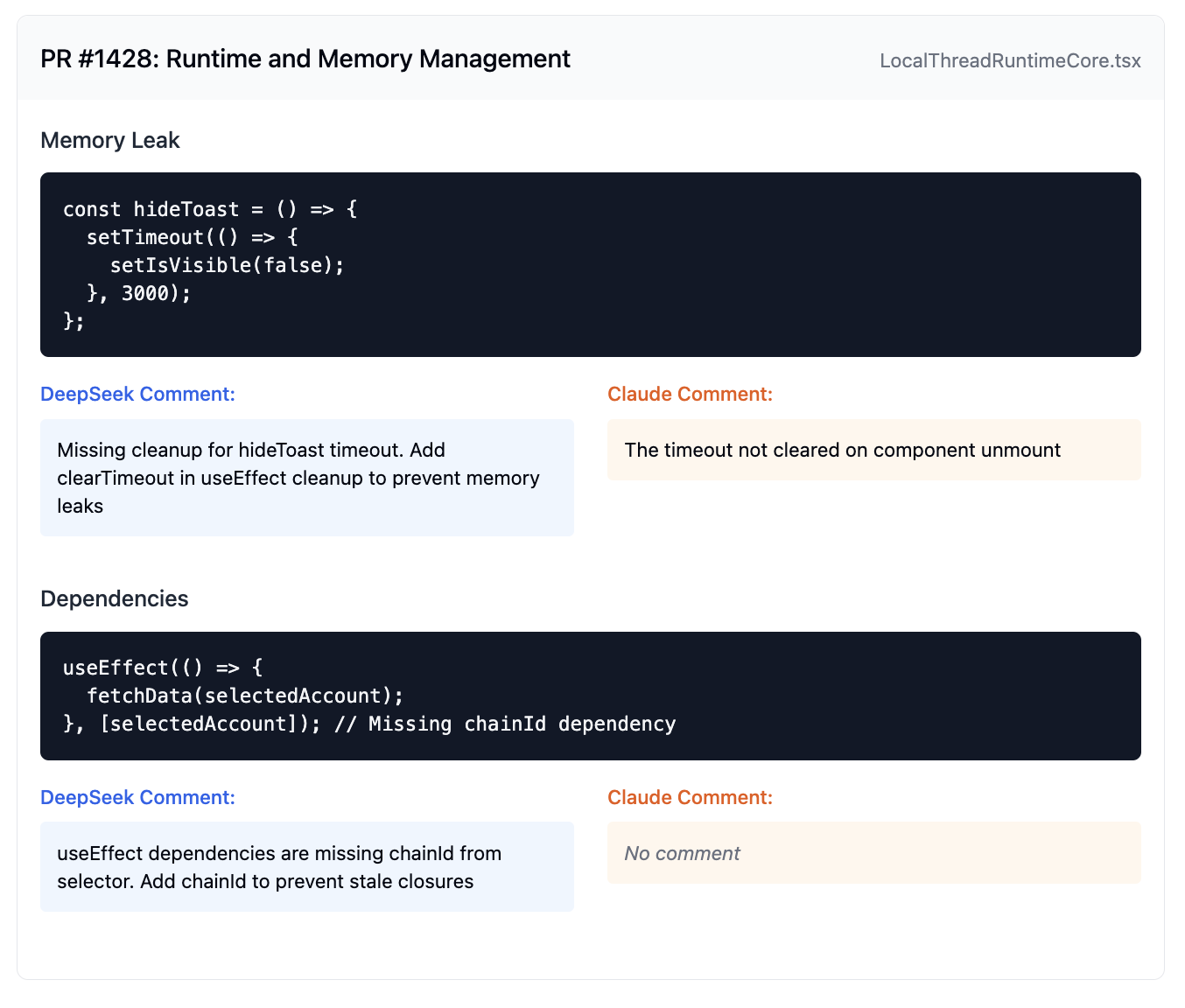
- ✅ Full context of hideToast timeout issue:
- - Identified memory leak
- - Found potential race condition risks after unmount
- ✅ Caught missing chainId in useEffect dependency array leading to stale closures
- ✅ Detected incompatible types between BaseThreadRuntimeCore and ModelConfigProvider/ModelContextProvider
- ⚠️ Mentioned timeout not being cleared but missed race condition implications
- ❌ Missed the stale closure issue with chainId dependency
- ❌ Did not catch the architectural type mismatch issue
PR 1442: External Message Converter Updates
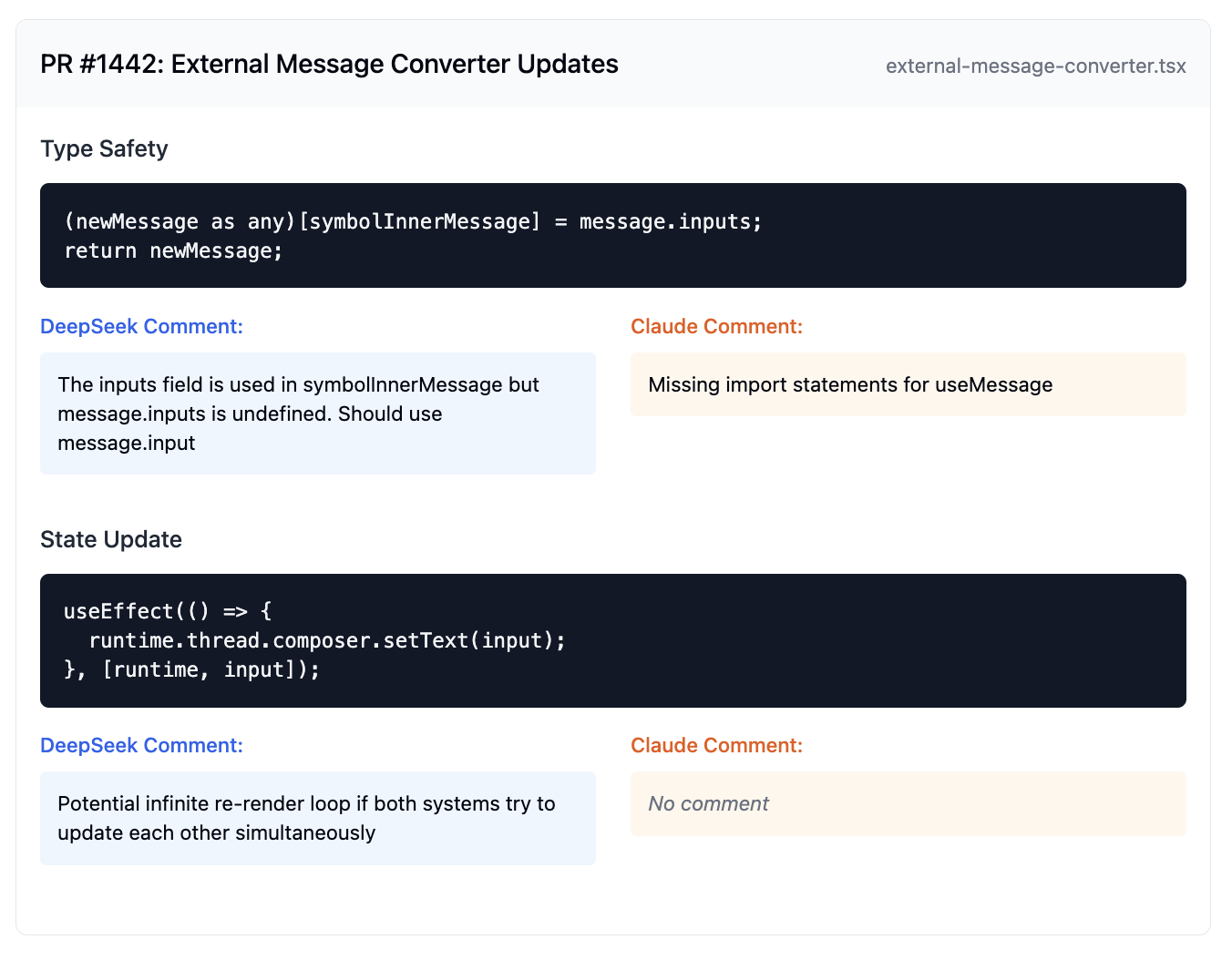
- ✅ Found incorrect property access (message.inputs vs message.input)
- ✅ Identified potential infinite re-render loop from concurrent state updates
- ✅ Detected missing null checks on specific metadata properties
- ❌ Only caught missing imports, missed property access issue
- ❌ Missed the concurrent state update re-render loop
- ⚠️ Noted need for validation but didn't specify which properties needed checks
Conclusion:
It's extremely impressive to see how well Deepseek managed to reason through race conditions, constructor mismatch issues and more. Though I've only highlighted 3 PRs in this blog, as we went through all 500 PRs in the analysis, I was consistently impressed at how Deepseek managed to perform better than Claude. Overall here are the main theme areas where Deepseek provided the most value:
Better Runtime Understanding:
- Identifies race conditions
- Catches state management issues
- Understands component lifecycle implications
- Identifies both immediate and downstream effects
- Catches subtle interaction issues
- Provides specific rather than generic feedback
- Names specific properties and types
- Explains exact error scenarios
- Provides more actionable feedback
Deepseek's ability to provide more precise, actionable feedback is a game changer for our PR review process. We're excited to see how we can leverage this model to improve our code quality and reduce the number of bugs that make it to production.
Catch Bugs Faster - Get Started with a Free Trial
Book a call with the founder