Entelligence Token Router : Opus-quality coding agents at half the cost
Enterprise spend on AI coding tools jumped more than 7x to ~$4B in 2025, enough that flat-rate pricing is breaking: Anthropic capped Claude Code; Cursor and GitHub Copilot moved to usage-based billing. Token Router is an enterprise gateway built to bring that bill down, serving each of your agents' model calls the cheapest way that still clears your quality bar. It ships with two tiers: Balanced, for teams that want frontier-level quality at lower cost, and Eco, for teams that want to save as aggressively as possible on everyday work.
The fair question for any cost-saving router is what you give up in output. To answer that, we ran Claude Code through both tiers and through the frontier models teams pay for today, across 45 real coding tasks graded by hidden test suites. Balanced matched Claude Opus 4.7 on quality, solving the same number of tasks, at about half the cost.
Key findings
Balanced matched Opus, 25 tasks to 25 out of 45, at about half the cost. Same number of tasks solved on the same benchmark, for ~50% of what the Opus run actually cost.
Eco solved more than Sonnet, 22 to 17, at ~28% of Sonnet's cost. Sonnet is the usual step down from Opus; Eco beat it on both quality and cost.
Cost per solved task, against Opus: Eco 29%, Balanced 50%, Sonnet 135%. Per task actually solved, Sonnet costs more than Opus.
Token Router out-solved openrouter/auto, 25 and 22 to 16. Router against router on the same 45 tasks; Eco beat it on both quality and cost, and openrouter/auto landed below bare Sonnet too.
Early read on Sakana's Fugu: Eco 7, Fugu 5 on 8 easy/medium tasks. The Fugu run is incomplete (we hit credit limits); a full comparison is coming in a follow-up.
How routing works
Underneath each tier, the router works across three levels: cheap for trivial and throwaway turns, mid for the main loop, and frontier for the hardest work (each level is backed by at least one model). On every call, it decides which level should handle that turn, reading what the turn is (a new instruction, a subagent exploring, a tool result coming back, a test that keeps failing) and serving it with the cheapest model that can handle it. When the current model can't read an image, the router hands it to a vision-capable subagent and feeds the result back to the main model. Because switching models throws away the warm prompt cache (most of the cost in a long session), it won't switch just to shave a little. Here's how that plays out on a single bug ticket:
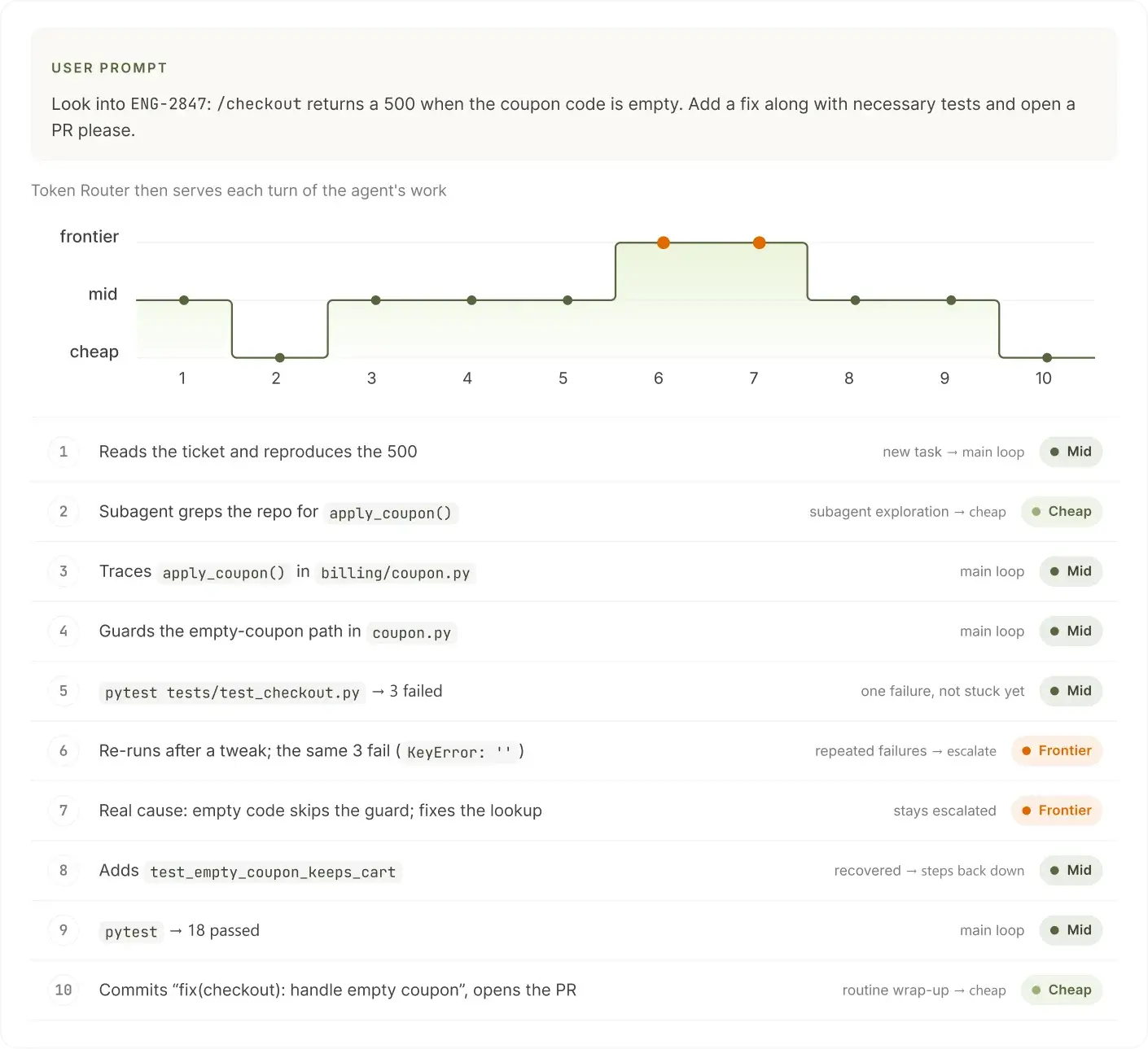
Most turns run on the cheap and mid levels. The frontier level comes in only when the agent is genuinely stuck (here, the same tests failing twice), and it drops back down once the work is moving again.
Eval setup
We used terminal-bench. Each task is a Docker image with a repo in some broken or half-finished state, an instruction, and a hidden test script. We run Claude Code inside the container for up to 40 turns, about 15 minutes, and then run the tests. A task counts as solved only if its own tests pass.
We ran the same agent on the same 45 tasks four ways: Opus directly, Sonnet directly, and through Token Router's Balanced and Eco tiers, each in fresh containers. Nothing changed between runs except what served the calls. Cost is the actual dollars each run billed, with prompt caching on as in normal use. Because the models aren't deterministic, we treat differences of one or two tasks as noise.
The 45 span a deliberate range, from sanity checks and small self-contained problems through everyday bug fixes and environment repair, algorithms and solver puzzles, data engineering and parsing, and domain-specialized work in fields like cryptography, bioinformatics, and chemistry. Roughly a third are trivial-to-easy, a third are ordinary engineering work, and a third are genuinely hard. No model we tested, Opus included, clears most of that hardest third, which is what gives the benchmark room to tell the models apart.
The harness behind these runs is at router-evals. It's the same setup we used for every number in this post, and if you'd like to check the results for yourself, it's all there to run.
Results
Balanced matched Opus task-for-task at half the cost
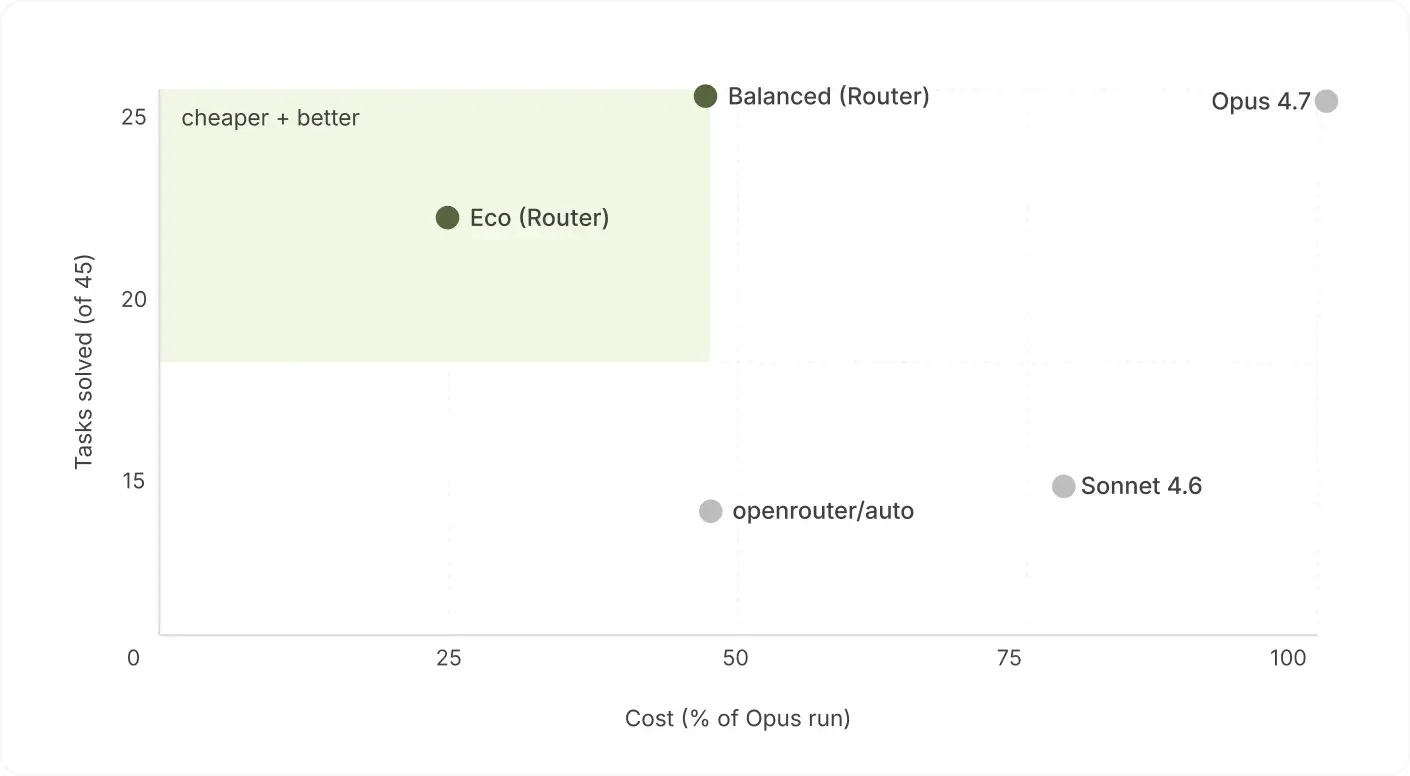
Balanced solved 25 of 45, the same count as Opus, at about half the cost: ~$16.50 against Opus's $32.67. Eco solved 22 for $8.43, about a quarter of Opus. Sonnet, the usual cheaper-than-Opus pick, solved 17 at $29.96, or 92% of Opus's cost for eight fewer solves.
Up and to the left is cheaper and better. Balanced sits directly under Opus at half the cost, Eco is cheaper still, and Sonnet and openrouter/auto sit lower, with fewer tasks solved.
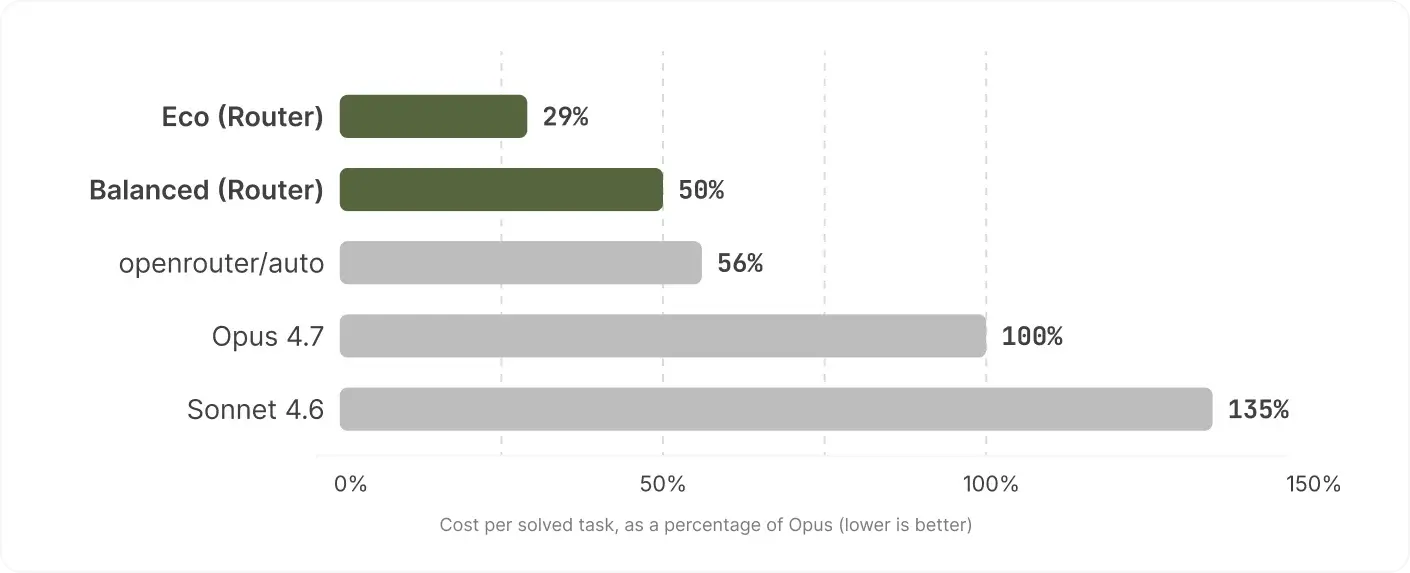
Per solved task, Sonnet costs more than Opus
Per-token price is the wrong yardstick on its own: a model that's cheaper per token but solves fewer tasks can cost more per result. Cost per solved task captures both. Measured against Opus, Eco solves a task for 29% of the cost and Balanced for 50%. Sonnet lands at 135%: it solves few enough that, per task actually completed, it costs more than Opus. openrouter/auto sits at 56%.
Sonnet missed a cluster of tasks the router solved
Balanced and Opus tied at 25. Task by task, the picture is less even: Sonnet missed several tasks that both Opus and the router solved.
Seven tasks were solved by both Opus and Balanced but failed by Sonnet: heterogeneous-dates, count-dataset-tokens, gomoku-planner, break-filter-js-from-html, db-wal-recovery, distribution-search, and huarong-dao-solver. On two more, chess-best-move and classifier-debug, Balanced passed where both Opus and Sonnet failed. Balanced also missed two that Opus solved, deterministic-tarball and feal-differential-cryptanalysis.
The totals land even at 25 because the misses and the extra wins cancel. But if your cost strategy today is dropping from Opus to Sonnet, the per-task view is what you're actually buying: a handful of tasks that stop getting solved. Balanced kept them.
Eco beat Sonnet by five tasks at ~28% of the price
Eco is the tier for teams that want the savings to be aggressive. It solved 22 of 45 to Sonnet's 17, for ~28% of what Sonnet cost.
A separate 10-task run we did earlier came out in the same order: Eco 9, Sonnet 8, Opus 7, with Eco's cost per solved task again about a third of Opus's. Small sample, same direction.
Token Router solved more than openrouter/auto
openrouter/auto, OpenRouter's automatic model router (powered by NotDiamond), picks a model per request from a pool of frontier models. On the same 45 tasks, it solved 16, compared with Balanced's 25, Eco's 22, and Sonnet's 17.
Across its 210 calls, 89% went to one model, GPT-5.5, and the rest to smaller Gemini models. It cost $11.67 (36% of the Opus run) at a median of 20 minutes per task. Of the 29 tasks it didn't solve, 22 ran out of the agent's budget before finishing and 3 returned a wrong answer. Two notes on the cost: the $11.67 is OpenRouter's billed price, while our tier numbers are raw provider cost; and this run had no time limit, while our tiers stopped at about 15 minutes per task.
Run it yourself
Available to enterprise customers next week
Token Router is getting launched next week. If you're looking to optimise your coding agent spend without impacting your output quality, request access.
What's next
We've also started running Sakana's Fugu on the same harness, but the run is incomplete: the account hit its credit limit after 8 easy-to-medium tasks, with Eco and Opus each solving 7 and Fugu and Sonnet each solving 5. That's the easy end of the distribution, not comparable to the 45-task results above, and we never reached its top tier, fugu-ultra. We'll run the full benchmark and follow up in a later post.