Loop Engineering Explained: Why the Hardest Part of AI Isn't the Model Anymore
AI engineering has shifted from optimizing isolated model outputs to managing autonomous, long-running tasks. Whether it’s a coding agent debugging a repository or a research agent gathering sources, the prompt is now just one part of a larger, iterative workflow.
Once an AI system starts operating like that, the prompt becomes the smallest part of a much larger workflow.
That's why you've probably started seeing the phrase loop engineering appear everywhere over the last few weeks.
When Boris Cherny, the engineer behind Claude Code, said, "I don't prompt Claude anymore. I have loops that are running. My job is to write loops," many people interpreted it as another attempt to declare prompt engineering dead. I don't think that's what he meant at all.
Prompt engineering didn't suddenly stop mattering. We simply reached a point where getting one good response is no longer the difficult part. The difficult part is building a system that helps a model make fifty good decisions in a row, recover from mistakes, manage context, use tools correctly, verify its own work, and eventually stop only after the original objective has actually been achieved.
That's the problem loop engineering is trying to solve.
Ironically, the loop itself isn't particularly complicated.
Every autonomous agent follows roughly the same execution cycle. It receives some context, decides what to do next, calls a tool if necessary, observes the result, updates its understanding of the task, and repeats the process until it believes it's finished. If you strip away all the abstractions, the core execution loop is only a handful of lines.
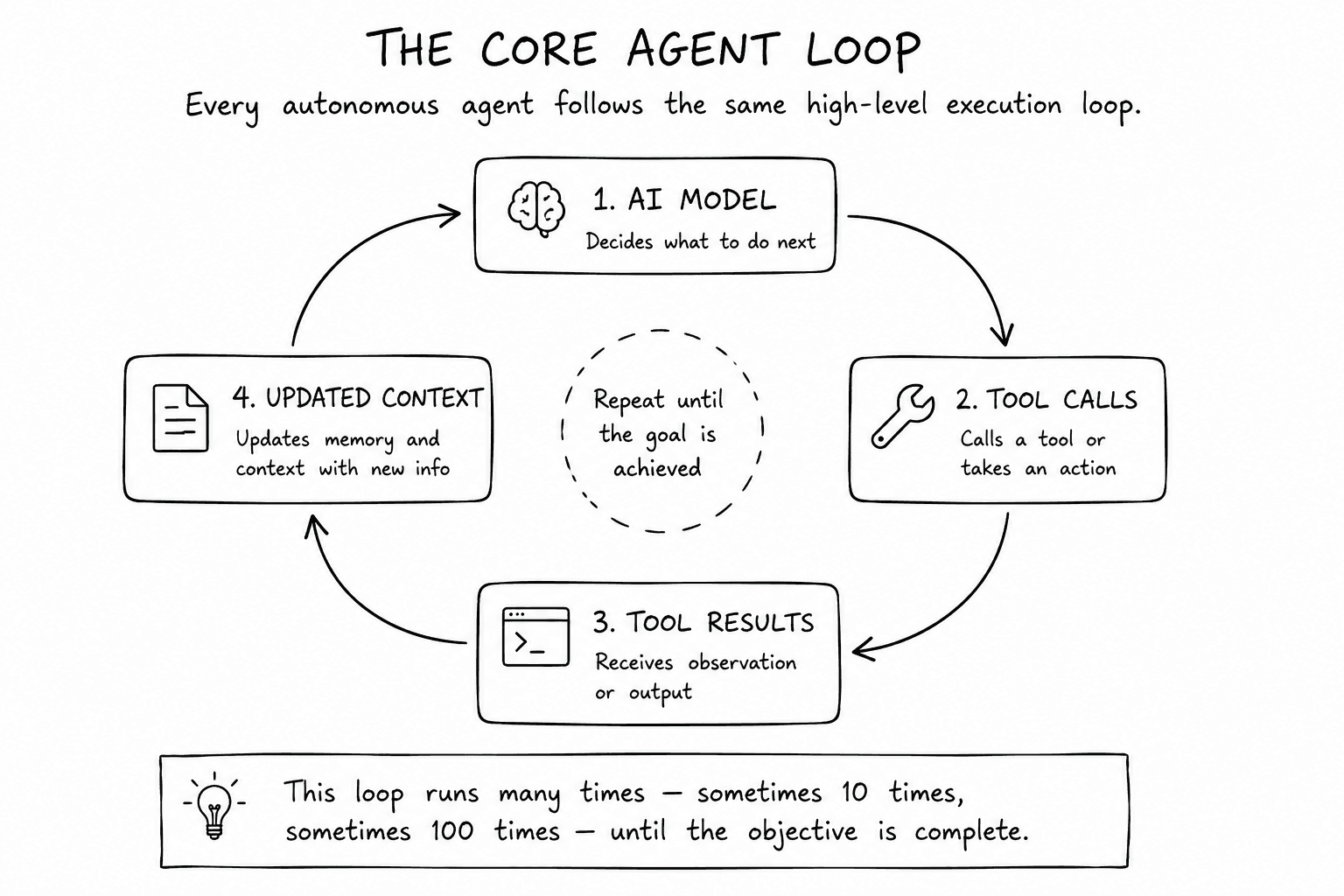
Almost every modern agent framework eventually converges on some variation of this same pattern. Whether you're building with OpenAI, Anthropic, LangGraph, OpenHands, or your own orchestration framework, the execution loop ends up looking remarkably similar.
That's exactly why I think the name "loop engineering" is a little misleading.
Nobody is building dramatically better AI products because they discovered a smarter while loop. The real engineering starts once you ask a much harder question: what needs to exist around that loop so the model can keep making good decisions for the next thirty minutes instead of the next thirty seconds?
That question shifts your attention away from the model itself and toward the environment where the model operates. Once you start looking at agents through that lens, the bottleneck in modern AI systems suddenly looks very different.
The important shift is that model quality is no longer the primary bottleneck. Increasingly, an agent's success depends on the environment around it, the quality of its tools, the way it manages context, and how its work is verified.
The prompt defines the objective, but the surrounding system determines whether the model actually reaches it. That's also why we think the next generation of developer tooling won't just help agents do work. It'll help engineers understand the work agents actually did. At Entelligence, we've found that visibility into execution often matters just as much as the underlying model. If the documentation is incomplete, the tools are unreliable, the context becomes noisy, or there's no reliable way to verify progress, even the smartest model will eventually make poor decisions. Give that same model a clean environment with good tooling and objective feedback, and the results become dramatically more reliable.
That's why I think one of the biggest misconceptions in AI right now is that better agents primarily come from better models.
Better models absolutely help, but they're no longer the whole story.
Imagine two companies building almost identical coding agents using the exact same frontier model. One agent edits a few files, repeatedly calls the wrong tools, loses track of the original objective, and confidently reports success while half the test suite is still failing. The other notices the failing tests, reads the logs, retries the failed commands, updates the implementation, reruns the verification pipeline, and only stops after every required check succeeds.
The intelligence inside both systems is identical.
What separates them is everything surrounding the model.
The industry has evolved from prompt engineering to context engineering, and now to loop engineering. This latest layer expands the scope of responsibility, requiring systems that can recover from failures and manage long-running objectives that prompts alone cannot solve.
That's also why I don't think loop engineering is another buzzword replacing prompt engineering.
It's a natural consequence of asking AI systems to perform work instead of generating responses.
Once an agent starts running for twenty, fifty, or even hundreds of iterations, new problems begin to appear that simply don't exist inside a normal chat conversation. The agent needs to know when to stop, what information should remain in memory, which tools it should use, how it should recover from failures, and how it can verify that the work it produced is actually correct instead of merely looking correct.
Those problems aren't model problems anymore.
They're systems problems.
And almost every production agent eventually runs into the same handful of them, regardless of which frontier model sits at the center of the loop.
The first problem almost every long-running agent runs into is surprisingly simple.
Agents often struggle to distinguish between ending a reasoning cycle and finishing a task. A coding agent might implement an authentication flow and stop once obvious actions are exhausted, even if integration tests are still failing.
Depending on the workflow, that success criteria might include things like:
Every unit and integration test passes.
The application builds without errors.
Browser automation completes successfully.
API responses match expected outputs.
Performance benchmarks stay within acceptable limits.
Security and linting checks pass.
Once success becomes something the system can verify objectively, the loop becomes significantly more reliable. The model is no longer responsible for deciding whether it's done. Its responsibility is simply to keep working until those conditions become true.
The second problem appears much more gradually.
People often assume giving a model more information automatically improves performance. That's generally true for short conversations, but long-running agents behave very differently because they continuously accumulate history.
Long-running agents suffer from "context rot" as they accumulate irrelevant history during tasks like debugging. Effective systems treat context as a limited resource, actively summarizing or discarding information to ensure the model focuses only on what is useful for the next decision.
Summarizing completed work instead of carrying every intermediate step.
Moving large tool outputs into external storage and retrieving them only when needed.
Splitting complicated subtasks into separate agent workflows before returning only the final outcome.
Retrieving relevant memories dynamically instead of permanently keeping everything inside the context window.
The goal isn't building agents that remember everything.
The goal is building agents that remember the information that's actually useful for making the next decision.
That's a subtle difference, but it's one of the reasons long-running production agents behave very differently from a chatbot with an extremely large context window.
Tool design turns out to be another place where intuition often points in the wrong direction.
The natural assumption is that giving an agent more tools automatically makes it more capable. More APIs, more MCP servers, more integrations, and more actions should mean the model can accomplish more work.
In practice, the opposite often happens.
Excessive tools can degrade performance by increasing the model's decision space. Reliable agents use a small set of well-defined, idempotent tools—such as a CRM record creator—that produce predictable outcomes even across hundreds of retries.
The final piece, and probably the one I find most interesting, is verification.
Verification must be separated from creation because models are better at justifying their work than grading it objectively. By using independent verifiers like unit tests or compilers, agents are forced to prove their success to an external system.
A unit or integration test suite.
A compiler or static type checker.
Browser automation validating a user flow.
A security scanner.
Another model acting as an independent reviewer.
A deterministic rule that returns a simple pass or fail.
Once you introduce an independent verifier, the behavior of the entire loop changes. Instead of trying to convince itself that the work looks correct, the agent is forced to satisfy an external system that doesn't care how confident the model feels.
That's a subtle architectural change, but I think it's one of the biggest reasons modern coding agents feel dramatically more capable than early generations. They're no longer expected to trust themselves.
They're expected to prove themselves.

Sometimes verification doesn't end when an agent produces the right output. In many real-world systems, the output itself becomes the next input. Code gets deployed. Workflows touch production. APIs serve real users. At that point, the loop extends beyond the agent and into the environment it just changed. The same principles still apply: observe the result, compare it against the objective, recover if necessary, and only stop when reality confirms the work is complete.
Verification tells you if an agent succeeded. Observability tells you how it got there. As these systems become more autonomous, that distinction is becoming increasingly important. It's one of the areas we've been exploring at Entelligence as long-running agents become the norm.
So Where Does This Go From Here?
I think that's the real reason loop engineering has become such an important topic over the last few months. It's not introducing a brand-new idea. It's giving a name to a shift that has already been happening across the industry.
The center of gravity is slowly moving away from the model itself.
We're already seeing that shift firsthand at Entelligence. The conversations we're having with engineering teams are becoming less about choosing the "best" model and more about building systems that are observable, reliable, and can improve over time. I think that's where the next wave of AI infrastructure will be built.
That's also why I don't think prompt engineering is disappearing, despite what some headlines might suggest. Prompting still matters. Context still matters. Better models will always matter. Loop engineering simply expands the scope of what we're optimizing. Instead of focusing on a single interaction with a model, we're designing systems that can repeatedly observe, reason, act, recover, verify, and improve until a real-world objective has actually been achieved.
As frontier models converge in capability, competitive advantage will shift from the model to the system surrounding it. The winners will be the teams that build systems allowing models to operate reliably for hours instead of minutes. That's the direction we're focused on at Entelligence, and I think it's where AI infrastructure is headed.
Eventually, every capable model will be able to reason. The harder engineering problem will be designing the environment where that reasoning consistently turns into useful work. That's what I think people are really talking about when they talk about loop engineering.