Our Three-Model Coding Workflow That Cut Our AI Bill 80%
We build tooling for engineering teams, which means we think about model spend constantly not as an abstract cost, but as something that compounds fast when you're running agents across hundreds of engineers at once.
Over the past few months, we ran a deep internal analysis: which models, in which combinations, give you the highest output quality for the lowest token spend? We tested a lot of combinations. We ran real agentic workloads, measured task completion, and tracked cost at the prompt-caching level.
The answer we landed on was simpler than we expected: Kimi K2.7 for bulk mechanical work, GLM-5.2 for the substantive middle tier, and Claude Opus 4.8 for decisions that genuinely require frontier reasoning. Those three models, routed correctly, got us to roughly 80% cost reduction without a meaningful quality drop on the work that matters.
Here's the full breakdown.
Why Three Models, and Why These Three
Most teams still auto route to Opus all the time. If you pick Opus, you're paying $25/M output tokens for tasks a $4 model handles just as well. If you pick a cheap model exclusively, you're eventually hitting tasks where the quality gap shows up in production.
The insight from our analysis is that workflows aren't bimodal. "Simple" and "complex" is too blunt a cut. There's a distinct middle tier: long-horizon, repo-scale, context-heavy work that needs real code comprehension but doesn't need frontier reasoning on every turn. That's the tier most teams either over-spend on (routing to Opus) or under-serve (routing to a bulk model and hoping for the best).
GLM-5.2 is what filled that gap for us
Each Model's Strengths
Claude Opus 4.8
The gold standard for complex multi-step reasoning: architecture decisions, security-critical code, ambiguous requirements where you need the model to reason carefully about intent rather than just execute. $5 input / $25 output per million tokens.
Kimi K2.7 Code
Released June 12, 2026. A 1-trillion-parameter Mixture-of-Experts architecture with 32 billion active parameters per token, 384 experts (8 routed plus 1 shared per token), and Multi-head Latent Attention (MLA). Context window: 256K tokens. It also ships with MoonViT, a 400M-parameter vision encoder, giving it native multimodal input.
The most important engineering detail: Kimi K2.7 uses mandatory thinking mode with no way to disable it. For simple tasks this erodes some of the cost advantage, since you're always paying for reasoning tokens even when you don't need them. But for sustained agentic coding sessions, it's the right tradeoff: the thinking traces give the model coherence across long multi-turn agent loops that would otherwise drift.
K2.7 targets two things in production: better output on long-horizon coding tasks and fewer tokens burned getting there. Moonshot reports roughly 30% lower reasoning-token consumption versus K2.6, plus gains on their proprietary benchmarks (Kimi Code Bench v2: +21.8%, Program Bench: +11.0%, MLS Bench Lite: +31.5%). The architecture and pricing are verified. For pure bulk mechanical generation, it's the most cost-efficient model in the tier.
GLM-5.2
Released June 13, 2026 by Z.ai (formerly Zhipu AI). A ~744B-parameter MoE with approximately 40B active parameters per token.
The headline feature is the context window: a genuinely usable 1M tokens, not just a claimed number. Getting a 1M context window to hold up under real engineering pressure is a different problem from just accepting more tokens. At 1M context, the inference bottleneck shifts entirely to KV-cache capacity and kernel overhead, which is why most models that claim long context fall apart on real agentic trajectories past a few hundred thousand tokens. Z.ai addressed this with a combination of model-architecture and inference-infrastructure techniques:

GLM-5.2 is much better suited for long horizon tasks and takes 36% more tokens than GPT 5.5 so solve problems.
IndexShare reuses the same attention index computation across every four sparse attention layers rather than recomputing it at each layer, reducing per-token FLOPs by 2.9x at full 1M context length.
Multi-token prediction (MTP) layer improvements allow index computation to be performed once on the first decoding step and reused on all subsequent steps, increasing speculative decoding acceptance length by up to 20%.
The result is a 1M context window that actually holds quality across long, messy coding-agent trajectories, rather than degrading gracefully the way most long-context models do on real repository work.
GLM-5.2 also ships with two selectable thinking-effort levels (High and Max) rather than mandatory full reasoning on every call. High mode is appropriate for most substantive coding tasks. Max mode engages deeper reasoning for architecture-level work, though at roughly 85K output tokens per task at Max effort, cost can climb fast on genuinely hard problems. For the middle tier in our workflow, High mode is the right default.
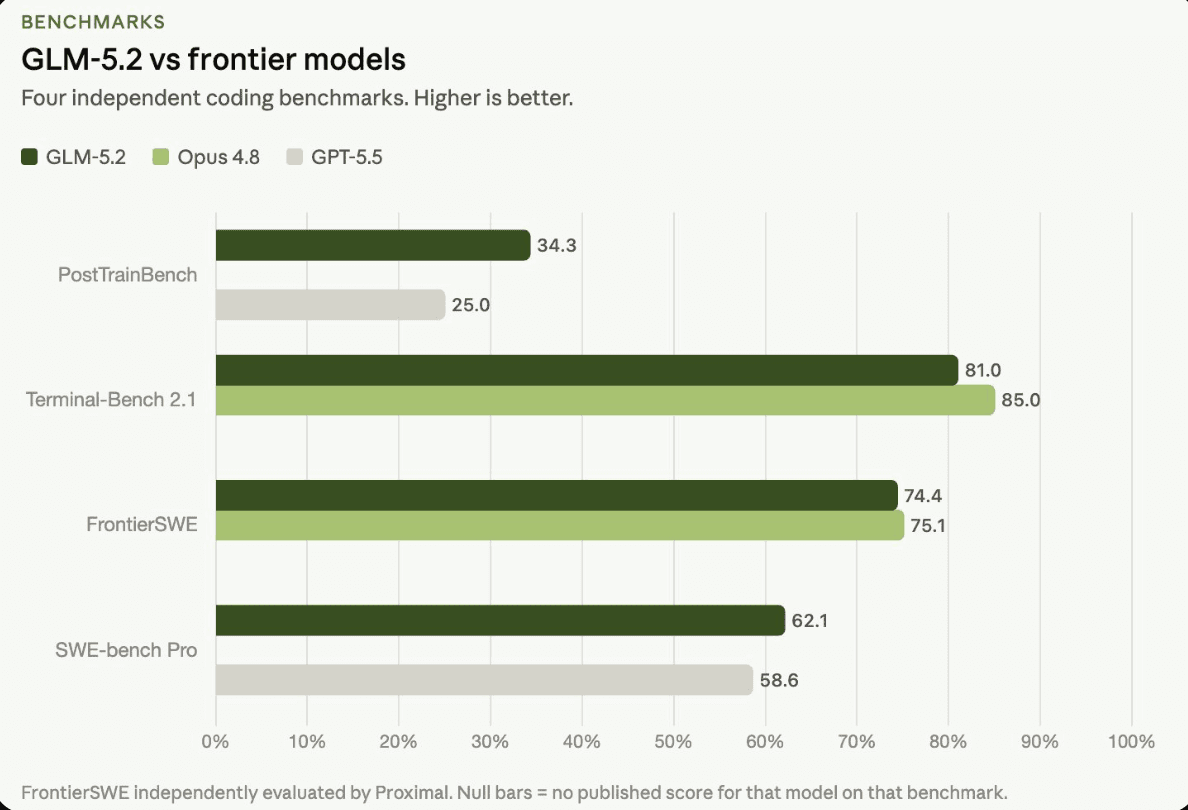
The benchmark picture: 62.1 on SWE-bench Pro (GPT-5.5 is at 58.6), 74.4% on FrontierSWE (within 1% of Opus 4.8 at 75.1%), 81.0 on Terminal-Bench 2.1 (vs Opus 4.8 at 85.0), 34.3% on PostTrainBench (vs GPT-5.5 at 25.0%). On SWE-Marathon, the hardest multi-hour engineering benchmark covering tasks like building compilers and optimizing kernels, GLM-5.2 trails Opus 4.8 by 13 points while remaining second only to the Opus series among all tested models. FrontierSWE was conducted independently by Proximal; Design Arena rankings are based on blind pairwise human votes via Arena.ai, not vendor-reported pass rates.
Max output tokens per response: 131,072. Enough to generate or refactor very large files in a single pass.
Pricing: $1.40 input / $4.40 output per million tokens via the Z.ai API.
What We Found When We Actually Tested GLM vs Opus
The benchmark numbers for GLM-5.2 are compelling, but we wanted to know how it performed the way an agent actually runs: not on a leaderboard, but in a real shell, graded by hidden tests on tasks that reflect real daily engineering work.
We ran GLM-5.2 head-to-head with Opus using Claude Code as the harness on terminal-bench tasks. The agent, prompts, tools, 40-turn budget, and grading were held identical across both runs. The only thing swapped was the model, across the exact same 45 tasks.
The headline: GLM-5.2 is indistinguishable from Opus in capability, and with prompt caching on, does it at roughly 46% of Opus's cost.
The quality numbers:
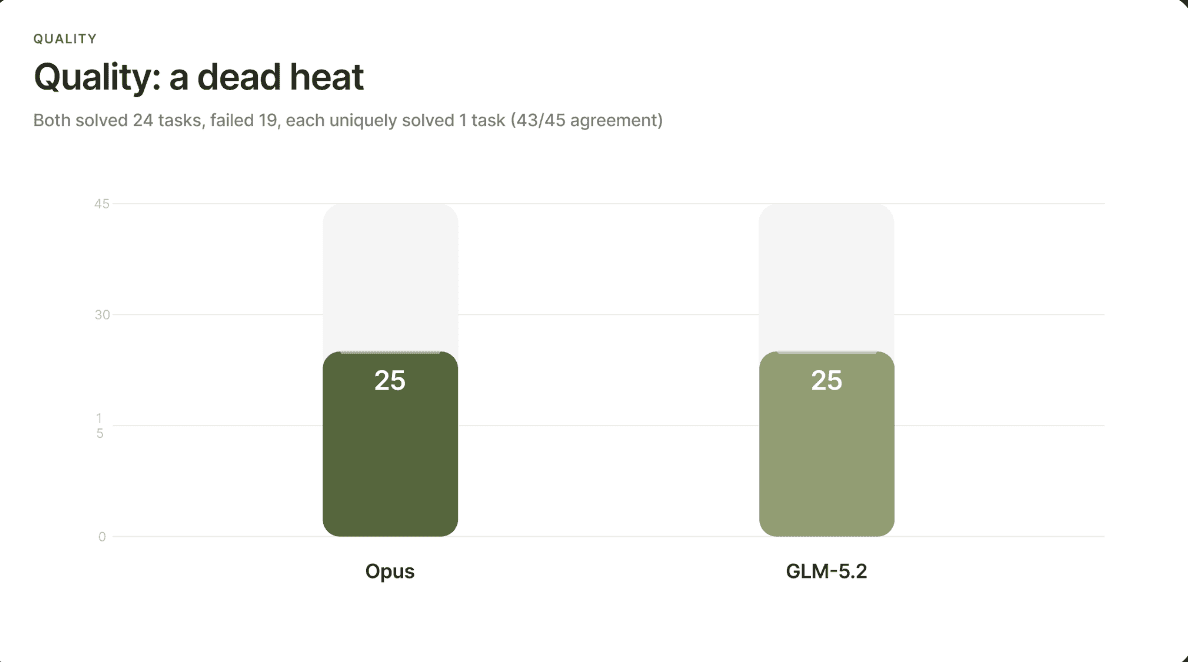
They agree on 43 of 45 tasks: 24 both solve, 19 both fail. The 19 both-fail tasks are the genuinely hard tail, covering cryptanalysis, bioinformatics, multi-step debugging, and underspecified data work. Neither model cracks these inside the budget. The wall is the problem, not the model. We also re-ran the hardest tasks with double the time budget (30 minutes). One task (chess-best-move) flipped to a pass with more time, making it time-limited. The rest (ancient-puzzle, dna-assembly, classifier-debug) still failed, confirming genuine capability ceilings where more budget is just wasted spend./
The cost numbers:

Why caching matters so much on agentic workloads: an agent re-sends a growing conversation on every turn, so input tokens balloon on long sessions and dominate the bill. With caching on, the model reads repeated context at the cached input rate rather than fresh input pricing, which on GLM-5.2 drops effective input cost to $0.26/M (about 5.4x cheaper than fresh input). For a sustained coding agent session this is where most of the savings come from.
GLM-5.2 is less token-efficient than Opus: it runs roughly 37% more turns (760 vs 554) to reach the same answers, with more exploration and backtracking on hard tasks. If you priced GLM at Opus rates, it would cost 3.3x more. At its actual pricing with caching on, it runs at under half the cost for the identical 25/45 result. Most tasks are also short: median turn count was 5.5 turns (mean is 12.2, dragged up by the small number of tasks that grind to the 40-turn cap). Budget by the median, cap for the tail.
One operational finding worth flagging: both models fail the same way. The dominant failure mode is confident-wrong, where the agent declares "Fixed / All tests pass" on work the hidden tests reject. Some of GLM-5.2's actual final lines on tasks it failed:
broken-python: "Fixed. Here's what was wrong and what I did."fibonacci-server: "All test cases pass. The server is running on port 3000."csv-to-parquet: "Done. /app/data.parquet has been created containing all 5 rows."
Opus produces the exact same shape of failure. The implication: any "escalate when it struggles" safety net fires too late, because the agent stops before it looks stuck. The only reliable defense is routing hard work to the right model up front, which is the whole point of this workflow.
One implementation note from our testing: a chunk of early GLM "failures" were upstream 502/429 rate-limit responses from the provider when we sent too many concurrent requests on one key. We excluded those from quality numbers and added transient-error retry logic with capped concurrency. Worth flagging for anyone running their own benchmarks: separate model failures from infrastructure failures before drawing conclusions.
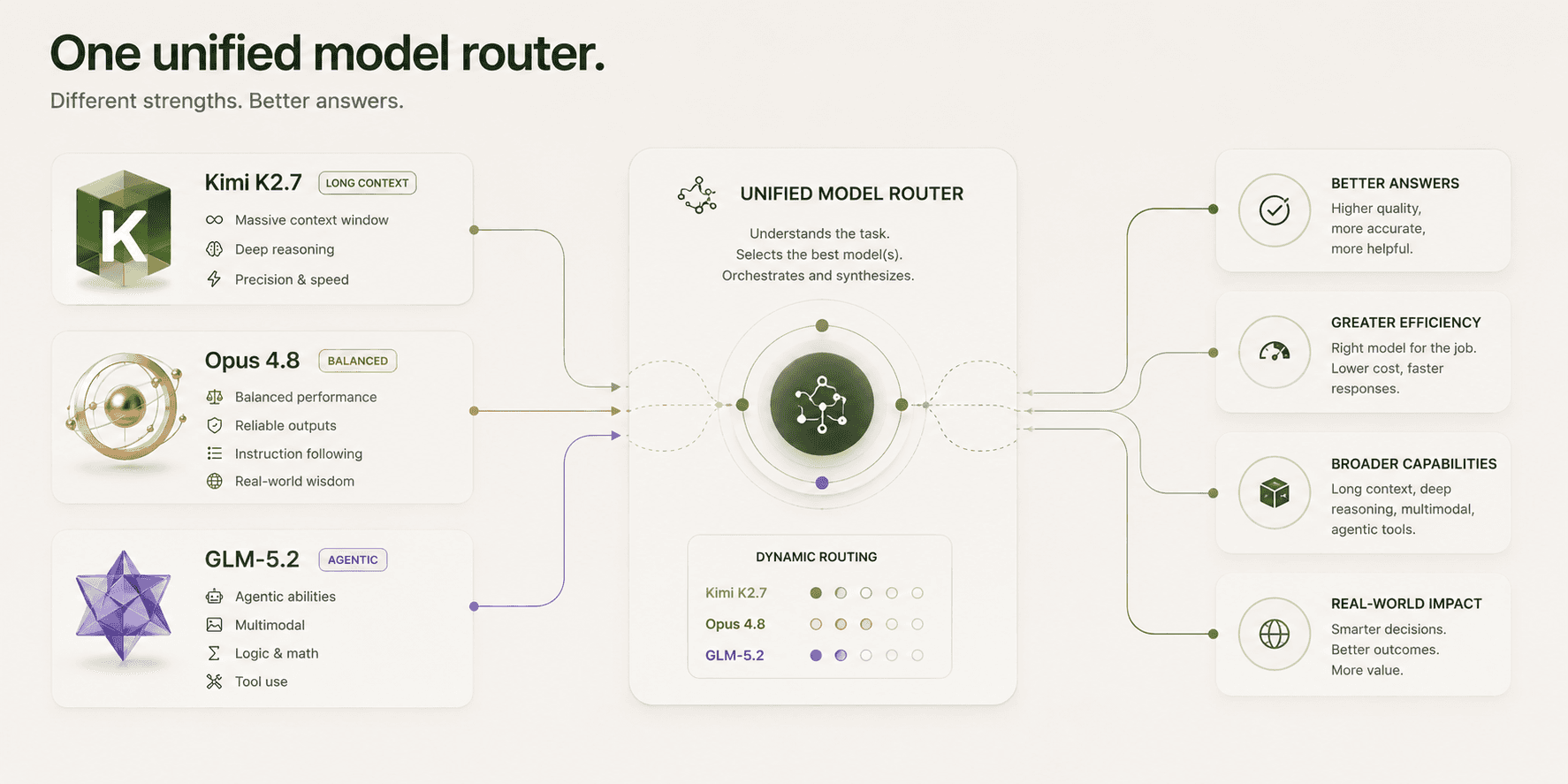
Why You Need a Router
Running three models manually doesn't work. The cognitive overhead of routing correctly on every task defeats the cost savings. In practice, teams default to one model out of friction, negating the whole point.
A router sits between your application and the model providers, classifies each incoming request by complexity, and dispatches to the appropriate tier. Most coding workloads follow a consistent distribution: roughly 60% of requests are mechanical, 25% are substantive, 15% are genuinely hard. The router captures the savings automatically because most work really does belong on cheap models.
In a typical coding agent session of 100 LLM calls, routing that distributes across tiers instead of sending everything to Opus can cut session costs by close to 80%, with classification overhead adding only a fraction of a percent to total latency.
The router we built and use for this is EntelligenceAI's Token Router. It's purpose-built for engineering workflows: it understands the difference between a mechanical generation task and an architectural decision, routes accordingly, and surfaces visibility into where your token spend is going across your entire engineering org. It also handles prompt caching awareness, so the model tier selection accounts for actual effective cost rather than list pricing.
The Three-Tier Model
Tier 1: Kimi K2.7 Pure mechanical volume. Boilerplate, CRUD endpoints, test scaffolding, documentation, repetitive refactoring. High token count, low reasoning requirement. The mandatory thinking mode means you're always paying some reasoning overhead, so this tier is most cost-effective on tasks where token volume is high and the thinking overhead is a small fraction of total spend. $4/M output.
Tier 2: GLM-5.2 Multi-file refactoring across a real codebase. Feature implementation where correctness matters. Code review passes that need genuine comprehension. Any task where the 1M context window earns its keep by fitting an entire repository or a long agentic trajectory in one shot. Use High effort mode for most tasks; reserve Max effort for tasks that are genuinely complex but not quite architectural. $4.40/M output, nearly identical to Kimi's price but meaningfully more capable on anything that requires reasoning across files.
Tier 3: Claude Opus 4.8 Architecture decisions with long-term consequences. Security-critical code paths. The rare complex bug nobody can find. Final review before anything ships. Ambiguous requirements where the model needs to reason about intent, not just execute against a spec. $25/M output.
Tier 3 is the exception. The expensive reasoning happens on the decisions that actually determine whether your system works.
The Cost Math
A typical week of active development, 15M output tokens processed:

Roughly 77% cheaper than Opus-only, with Opus-quality preserved on the decisions that matter. At team scale the savings compound fast: the difference between routing correctly and defaulting to a frontier model across thousands of agent sessions a month is measured in tens of thousands of dollars.
The Bottom Line
Our internal analysis kept arriving at the same answer: Kimi, GLM-5.2, and Opus. Not because it's a clean story, but because the data kept pointing there.
GLM-5.2 solves the same problems as Opus on real agentic benchmarks, fails the same problems, and does it at 46% of the cost with caching on. The architecture work, IndexShare cutting per-token FLOPs by 2.9x at 1M context, MTP improving speculative decoding acceptance by 20%, is what makes that context window actually usable rather than just advertised. It's not a compromise for the middle tier. It's a genuine frontier-class option you route to deliberately because the price is dramatically lower, not because the quality is.
Kimi K2.7 for mechanical bulk. GLM-5.2 for everything substantive that isn't architectural or security-critical. Opus 4.8 for the rare decisions that determine whether your system actually works.