


Faster Code, Slower Teams: The Paradox No One Warned You About
You Can Ship Code in an Afternoon. So Why Is Production Still Breaking?
The real bottleneck in engineering was never about writing code. It never was.
The Fastest It Has Ever Been to Ship
Here is where we are: a solo developer today, armed with Claude or Cursor or GitHub Copilot, can scaffold a feature, write tests, and push to production in a single afternoon. That same task would have taken a mid-sized team the better part of a sprint two years ago.
The velocity numbers are not projections. They are already showing up in the data. GitHub reported that developers using Copilot complete tasks up to 55% faster. Studies across multiple enterprise teams show AI-assisted developers merge pull requests nearly twice as frequently as before. And the macro signals are even starker.
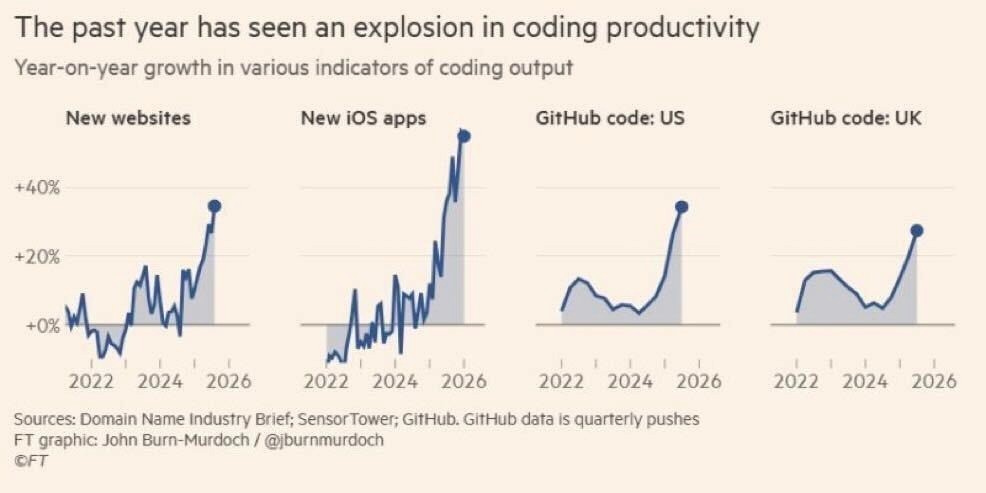 The past year has seen an explosion in coding productivity Year-on-year growth in new websites, iOS apps, and GitHub code pushes (US & UK)Source: Domain Name Industry Brief; SensorTower; GitHub · FT graphic: John Burn-Murdoch / @jburnmurdoch © FT |
New websites, new iOS apps, GitHub code pushes in both the US and UK: every single indicator is spiking upward into 2026 at rates not seen in the previous four years combined. Code is no longer the constraint. It has not been for a while now.
55% faster task completion for developers using AI coding assistants (GitHub, 2024) |
So the bottleneck has shifted. And if you are an engineering leader and you have not felt it yet, you will.
More Code, More Problems
There is a quote from Jyoti Bansal, CEO of Harness, that cuts right to it. He noted that his team is shipping more code than ever, yet it is actually slowing them down. That is not a contradiction. That is the new normal.
“We are shipping more code than ever before, and yet it is slowing us down.” Jyoti Bansal, CEO, Harness |
When you increase the volume of code shipping into production without increasing the quality of context behind that code, you are not accelerating. You are compressing risk. You are front-loading the debt. And production is where that debt gets collected, usually at 2am, usually during a spike in traffic.
The data reflects this. According to the Accelerate State of DevOps Report, organizations in the low-performing tier experience change failure rates as high as 64%. Meanwhile, DORA metrics show that elite engineering organizations recover from incidents in under one hour. The gap between these two groups is not talent. It is not tooling. It is context.
64% change failure rate in low-performing engineering organizations (DORA / Accelerate State of DevOps Report) |
Why AI-Generated Code Breaks Production
AI coding tools are genuinely impressive at what they do. They read your prompt, understand common patterns, and produce syntactically correct, often functionally sound code. The problem is the three things they do not know.
AI writes code without knowing your codebase, your history, or your incidents. |
1. Your codebase context
When a developer who has been on your team for three years touches a service, they carry mental models built over hundreds of PRs, incidents, and architecture decisions. They know which module is fragile. They know which library was swapped out after an outage in Q3. They know the implicit contract between two services that was never written down anywhere.
An AI assistant has none of that. It reads what is in the prompt and the files you give it. It makes educated guesses about the rest. And educated guesses at scale become production incidents.
2. Undetectable bugs at generation time
AI tools are excellent at catching surface-level issues. Syntax errors, obvious type mismatches, missing null checks. What they consistently miss are emergent bugs that only appear when the code interacts with your specific production environment, your specific data distribution, and your specific edge cases.
A McKinsey analysis of AI-assisted development found that while AI tools reduced obvious defect rates, teams still saw significant increases in complex, hard-to-reproduce production failures that required senior engineering time to diagnose. You traded easy bugs for expensive ones.
40%+ of production incidents in AI-assisted teams involve issues undetectable at code review (McKinsey Engineering Research, 2024) |
3. No memory of your past incidents
This is the most expensive gap. Every production incident your team has ever resolved is a lesson. There is an implicit curriculum in your incident history: what broke, why it broke, what the fix was, and what the blast radius looked like. Your senior engineers carry this. Your AI tools do not.
So the same class of bug surfaces again. The same race condition. The same misconfigured retry logic. The same assumption about how a downstream service handles timeouts. It is not that the AI makes the same mistake twice. It is that it never knew there was a mistake to begin with.
This is the core of the problem. You have unlimited code generation capacity and zero institutional memory in the tools generating that code.
What a Senior Engineer Actually Knows
Think about what makes a principal engineer valuable on a team they have been part of for years. It is not their ability to write code faster than a junior. It is the layers of context they bring to every decision.
They remember the outage six months ago that traced back to a pattern that looks innocent on the surface.
They know which part of the codebase carries undocumented assumptions that will silently break under load.
They recognize when a new feature is architecturally consistent with where the system is heading and when it is creating future debt.
They proactively flag what could go wrong before it does, based on what has gone wrong before.
Now consider what happens when you scale code output 10x with AI but the thing reviewing, approving, and learning from incidents is still just your human team operating at normal human speed. The leverage breaks.
Engineering teams today are producing more code than their review and incident-learning processes were built to handle. The output side scaled. The learning side did not.
The Loop That Learns
This is exactly the gap Entelligence was built to close. We built something that fundamentally changes the relationship between code output and production intelligence.
Entelligence operates as a self-healing, self-learning loop. Every time something breaks in production, the system does not just flag the incident. It trains on it. It builds a compounding memory of what your specific codebase has historically broken on, what patterns preceded each failure, and what fixes held.
The next time a pull request comes in that touches a similar pattern, Entelligence does not offer a generic lint warning or a noisy comment about test coverage. It surfaces the specific, contextual signal: this pattern has failed in production before, here is why, and here is what to watch for.
This is not static analysis. It is not a rule engine. It is institutional memory operationalized into your development workflow. The context your senior engineer carries, made available at the velocity AI code generation demands.
The result is engineering teams that do not just ship faster. They ship smarter. The code that goes into production has been reviewed against the real history of your system, not just the syntax rules that apply to every system.
The New Question Engineering Leaders Have to Answer
The question used to be: how do we help our engineers write code faster?
That question has been answered. The tools exist. The velocity is there. Any team of reasonable size with access to modern AI coding assistants can generate more code in a week than they could have in a month two years ago.
The question now is: how do we ensure that code actually behaves correctly in production, given that it was generated by a system with no knowledge of our history?
Teams that answer this question well will compound their velocity gains. Every feature ships faster, and more of those features ship clean. Incidents decrease. MTTR drops. The senior engineer's knowledge stops being the bottleneck, because it is no longer locked inside one person's head.
Teams that do not answer it will find that more code means more noise, more incidents, more time spent debugging patterns that have already been debugged before, and more of that 2am production chaos that was supposed to be behind them.
The bottleneck is no longer writing code. It is writing code that understands where it is going. |
Ship More. Break Less. Learn Continuously.
The era of AI-generated code is not the finish line. It is the starting gun for the next challenge in engineering: building systems that learn from production as fast as AI tools generate for it.
The teams that will win are not the ones with the most AI-assisted developers. They are the ones that close the loop between what ships and what breaks, automatically, continuously, and with the depth of context that only comes from real production history.
That loop is what engineering teams need now. Not more code generation. A smarter generation process.
Entelligence
Self-learning AI for production-grade engineering teams.
Try Entelligence Now.