


Inside Claude Code: What the Leaked Source Actually Revealed
Claude Code is Anthropic's terminal-based coding agent, and until March 31, 2026, nobody outside Anthropic knew how it actually worked under the hood.
On that day, a debug source map file called cli.js.map shipped inside a routine npm update, carrying 512,000 lines of the original TypeScript source across 1,900+ files. The code spread across GitHub within hours, hit 44,300 forks, and now lives on decentralized platforms Anthropic cannot reach.
In this article, let's look at what was actually inside it, and then break it down piece by piece.
The Architecture at a Glance
Claude Code is built around three core files that handle everything: QueryEngine.ts for model orchestration, Tool.ts for the 40+ agent capabilities, and commands.ts for the slash command system.
On top of that, there’s a four-layer memory architecture, a layered permission system for tool execution, a set of feature flags gating unreleased behavior, and internal model codenames that never made it to any public documentation.
The diagram below maps how these pieces connect.
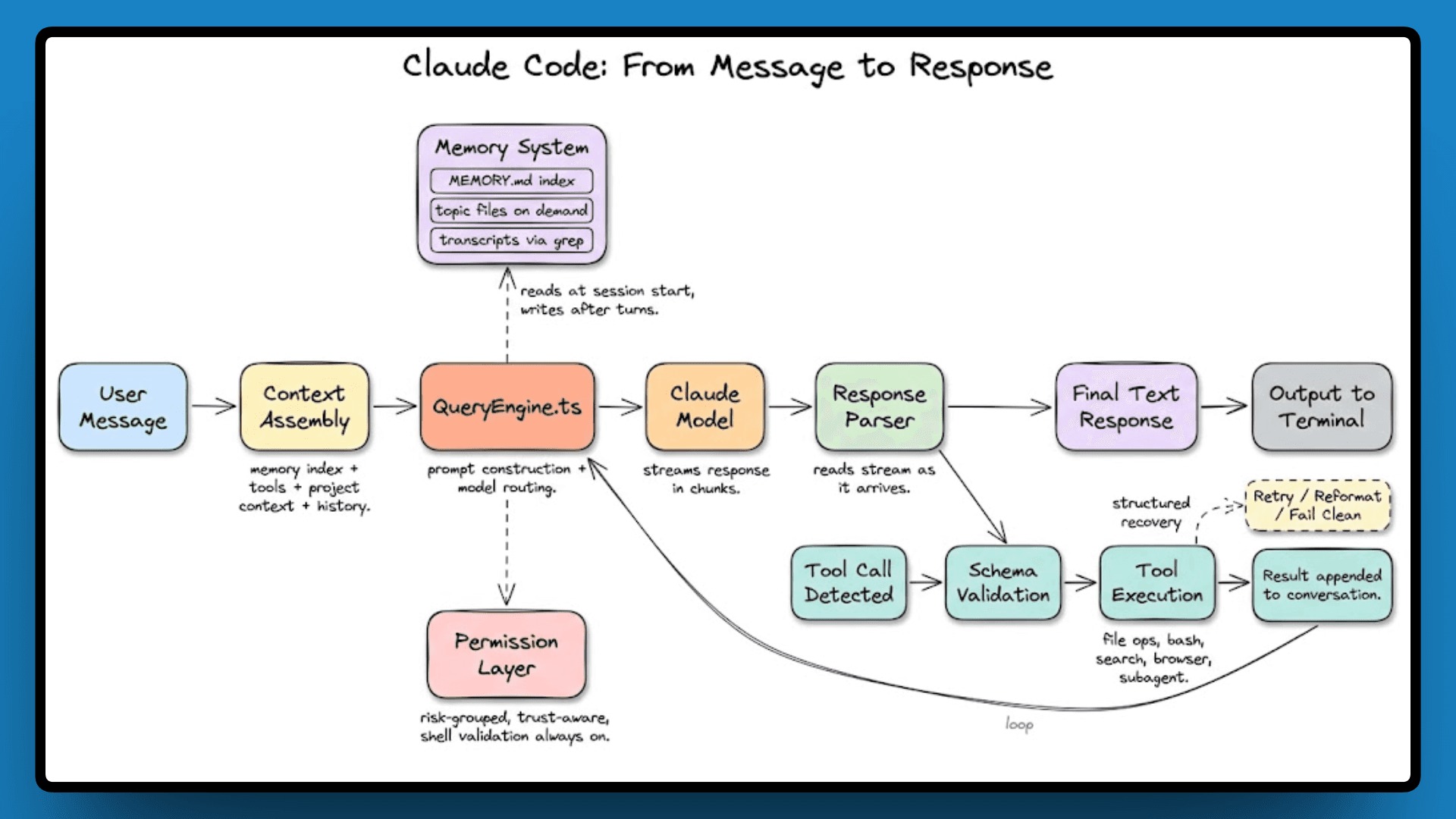
Let's go through each layer now, in the order they connect.
The Tech Stack: What Claude Code Is Actually Built On
Claude Code runs on Bun, uses React + Ink for the terminal UI, and is written entirely in TypeScript across 1,900 files and 512,000 lines.
Bun handles the runtime, React + Ink renders the terminal interface using the same component model you'd use for a web UI, and TypeScript ties it all together with strict typing across the entire codebase.
Within that codebase, three files carry most of the architectural weight:
File | Lines | Role |
|---|---|---|
| ~46,000 | LLM inference orchestration |
| ~29,000 | 40+ agent capabilities with permission schemas |
| ~25,000 | Slash command system |
These three are the structural pillars that everything else connects to, and the query engine is where it all starts.
The Query Engine: How Claude Code Talks to the Model
QueryEngine.ts sits at roughly 46,000 lines and owns the entire lifecycle of every model interaction, from assembling the prompt to parsing the response to deciding what happens next. Before a single API call goes out, the engine pulls together memory state, available tools with their schemas, project context, and conversation history. It constructs the prompt in a specific order rather than just appending everything it has.
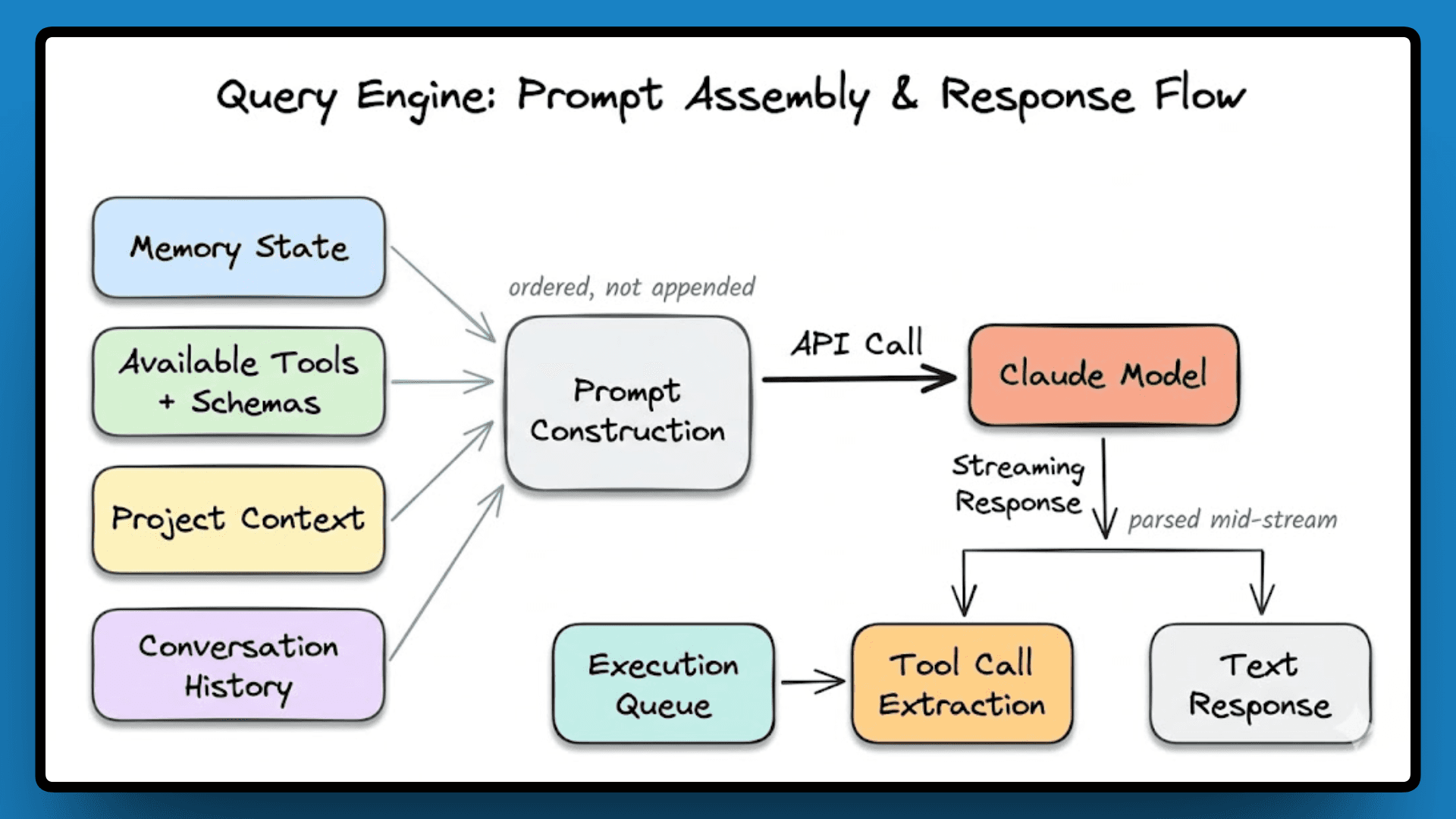
Responses stream back in chunks, and the engine parses them as they arrive. If the model returns a tool call mid-stream, the engine extracts it, queues it for execution, and keeps processing the rest of the stream without waiting for the full response to finish. Token usage is tracked live, and when the context window nears the limit, the engine triggers compression before it's actually hit.
The Agent Loop
Every response Claude Code gives is the result of one or more passes through a loop: build a prompt, call the model, parse the response, and if tool calls come back, execute them, append the results, and loop again. This continues until the model returns a final text response with no further tool calls, at which point the turn ends.
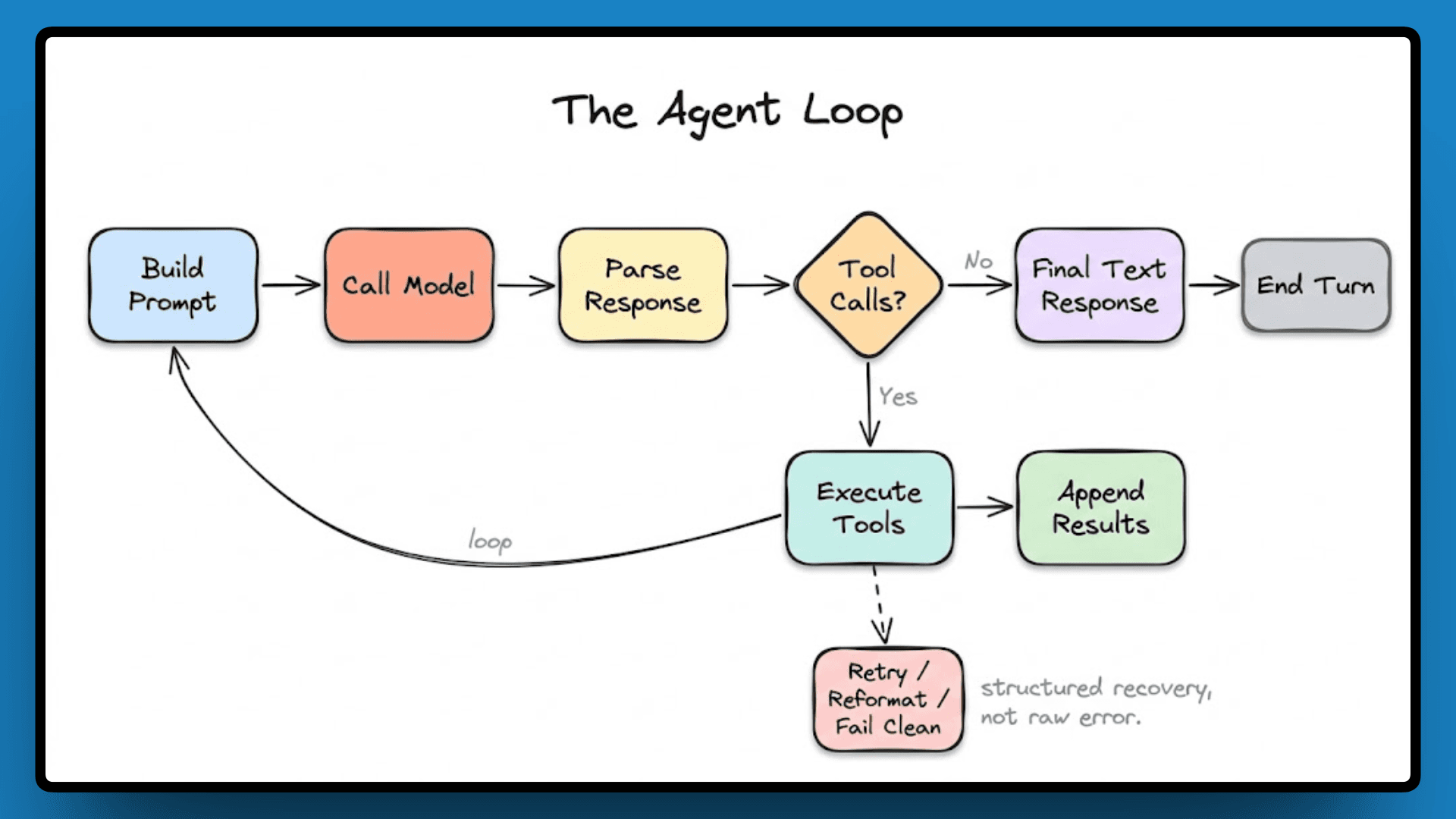
When a tool call fails or the model returns malformed output, the engine has structured recovery paths. It retries where it makes sense, reformats the tool result to give the model better information on the next pass, and surfaces a clean failure state when recovery isn't possible.
Context Compression: Not Truncation
When a conversation grows long enough to approach the model's context limit, most systems cut off the oldest messages. Claude Code instead runs an auxiliary model pass over the portion about to be dropped, extracts the key facts and decisions from it into a compact summary, and inserts that summary back in place of the full content.
Earlier reasoning doesn't disappear; it gets condensed, which matters for long-running tasks where decisions made early in a session are still relevant hours later.
Tools and Permissions: What Claude Code Can Actually Do
Tool.ts is the second major file in the codebase, at roughly 29,000 lines, and it defines everything Claude Code can do beyond generating text.
Every tool has four parts: a name, a description that the model reads to decide relevance, a JSON Schema for inputs, and an execution function. The model outputs structured JSON, the engine validates it, and if it passes, the tool runs. The result comes back as a new message, the query engine loops, and the model continues.
The tools cover file reads and writes, bash execution, web search, browser automation, subagent spawning, and memory read/write. Dedicated Grep and Glob tools handle search separately from bash, giving the model cleaner, structured results.
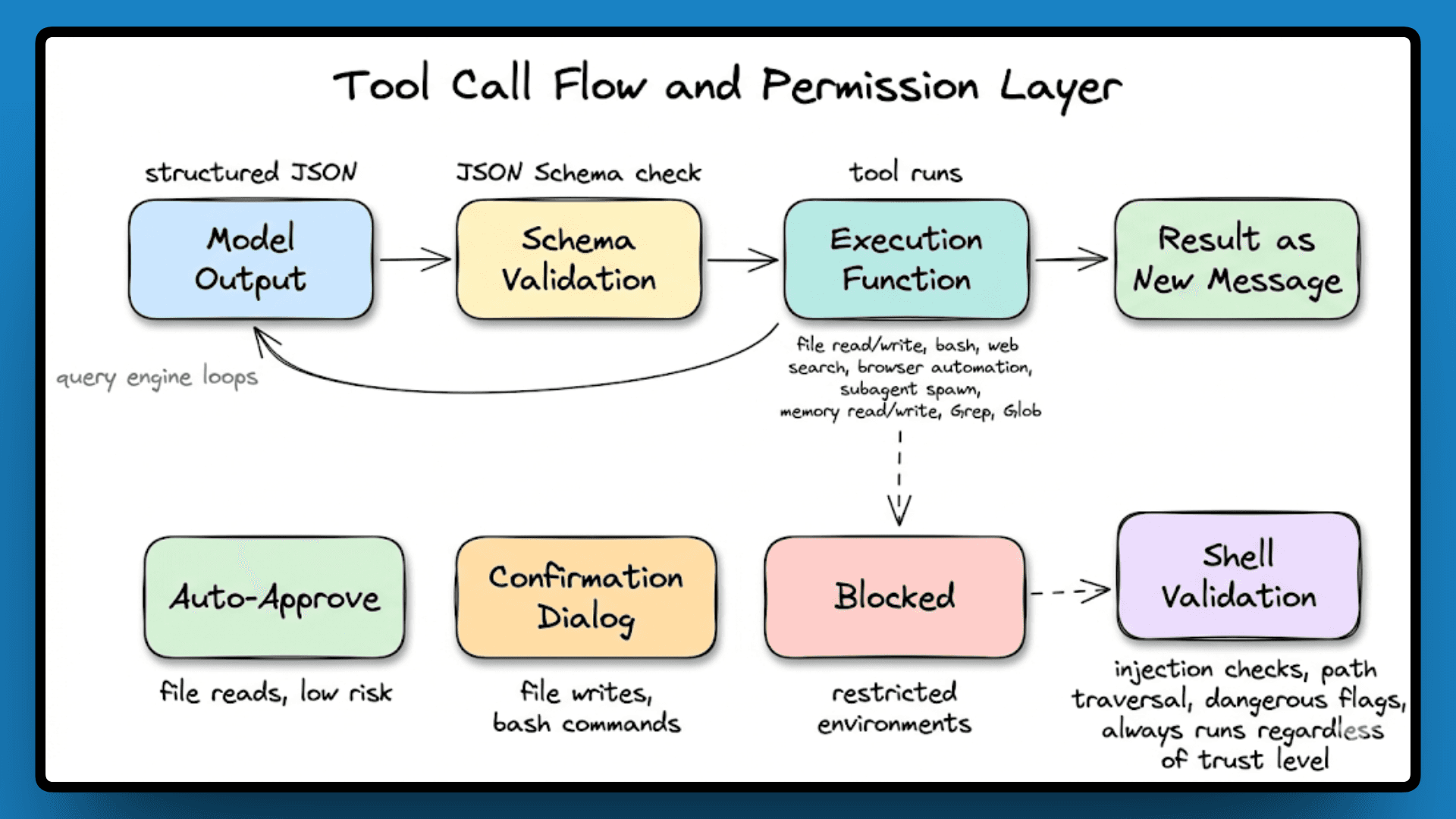
Permissions are grouped by risk:
file reads auto-approve,
file writes, and bash commands trigger a confirmation dialog, and
some tools are blocked entirely in restricted environments.
Claude Code lets you mark a directory as trusted at the project level, which expands the auto-approve set for that context, but shell commands still go through injection and path traversal checks on every execution, even in trusted environments.
That covers what Claude Code can do and what it's allowed to do. Now, next, let’s see how it remembers.
Memory Architecture
Claude Code doesn't load everything it knows into context each session. Two files load at the start of every session:
CLAUDE.md, which is the user-written rules file where you define project conventions and instructions, and
MEMORY.md, which is Claude's own memory index that it writes and maintains itself.
MEMORY.md contains only pointers, with actual content living in separate topic files that load on demand, and session transcripts never enter the context at all, only searched via grep when something specific is needed.
But the real design challenge is how it stays organized across hundreds of sessions, starting with the Memory Layer.
The Three-Layer Design
The memory system has three layers with clearly separated responsibilities.
Layer 1, the index. MEMORY.md loads at the start of every session, with each entry kept to around 150 characters, containing only pointers to where the actual content lives.
Layer 2, topic files. These hold the real content and load only when the model follows a pointer from the index, so the model pays the token cost only for what's relevant to the current task.
Layer 3, session transcripts. Never loaded into context directly. When the model needs something from a past session, it greps the transcript files for specific terms and retrieves only the matching portions.
This is what keeps the architecture viable for a persistent agent: the token cost remains predictable over months of continuous use rather than increasing with each session.
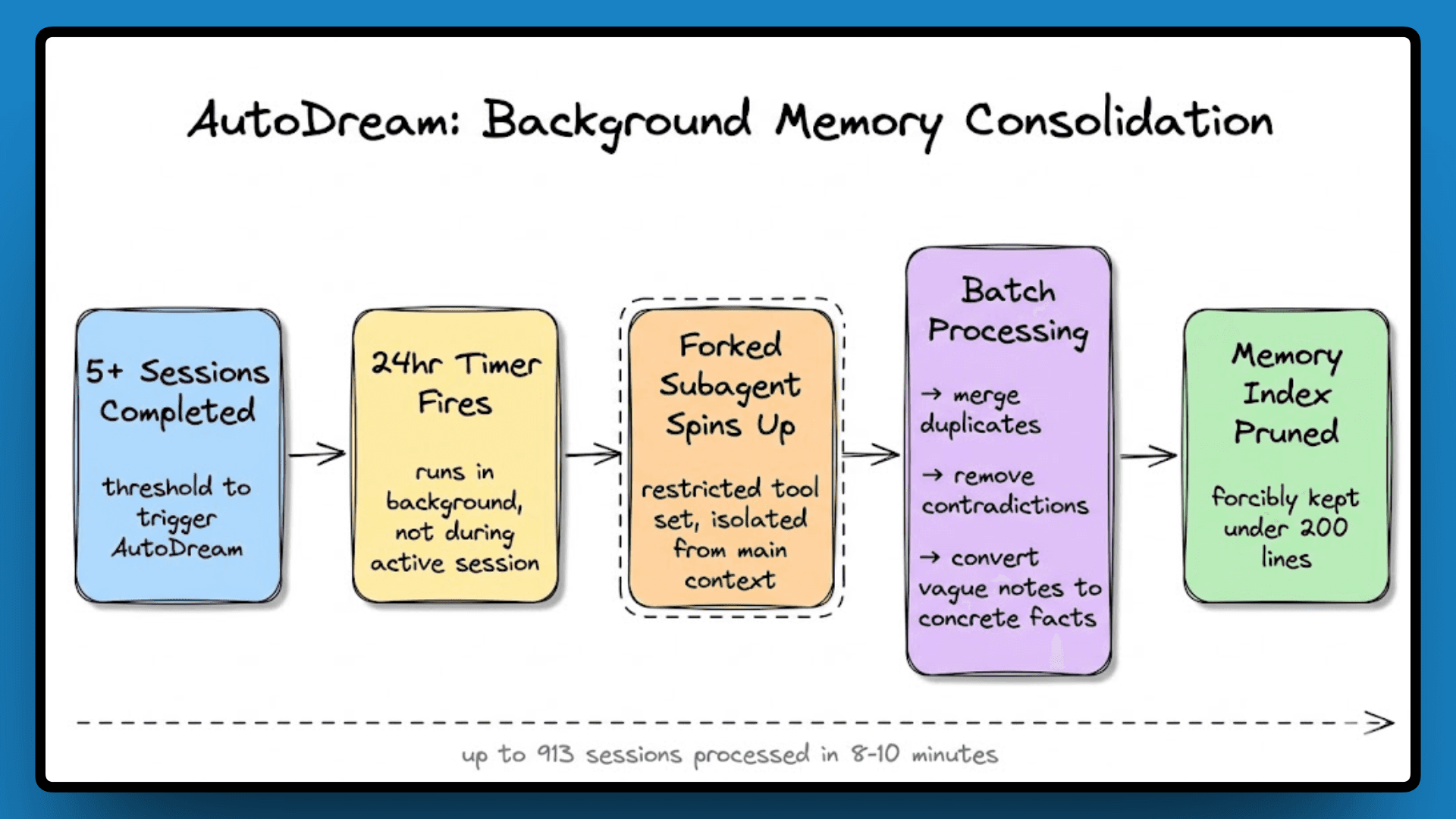
AutoDream: Background Memory Consolidation
After five or more sessions, a background process called AutoDream runs every 24 hours. It processes the session history in batches, merges duplicates, removes contradictions, converts vague notes into concrete facts, and then prunes the memory index back to under 200 lines.
AutoDream runs in a forked subagent with a restricted tool set, isolated from the main context so the consolidation process can't corrupt the state an active session is using.
Staleness as a Design Constraint
AutoDream handles consolidation, but there's a separate problem it doesn't solve: stored information going out of date as the codebase changes.
Claude Code handles this by simply not storing things that go stale. Derived facts like code structure, file paths, and PR history are never written to memory because they can always be re-derived from source, and storing them just creates entries that silently become wrong over time.
The model is also explicitly instructed to treat anything retrieved from memory as a hint, not a confirmed fact, and to verify it against the current project state before using it.
With the memory system covered, the more forward-looking part of the codebase is the feature flags, which are conditional switches in the code that hide fully built but unreleased systems, and reading through them is essentially reading Anthropic's internal roadmap for where Claude Code is heading next.
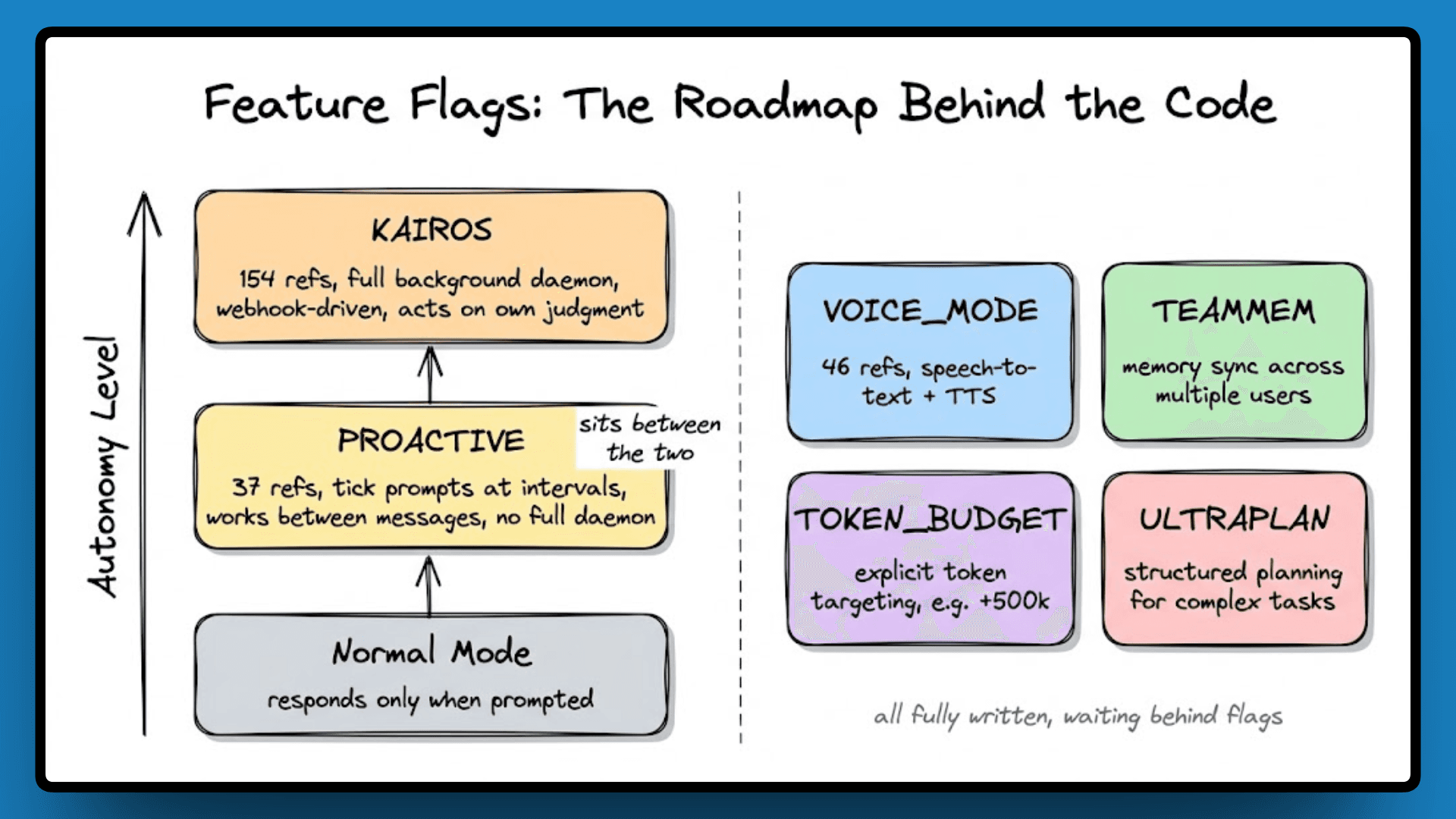
Feature Flags: The Roadmap Hiding in Plain Sight
The flags in this codebase aren't toggling small UI experiments; they gate fully written subsystems, with complete code behind each one, not stubs or prototypes, which means the features exist and are waiting to ship. A few of them are significant enough to change what Claude Code fundamentally is.
KAIROS: Always-On Autonomous Agent
With 154 references, KAIROS is the biggest shift in the codebase. Right now, Claude Code responds when you ask it to. KAIROS turns it into a background daemon that keeps running between your interactions, watches your repository via GitHub webhooks, reacts to events without being prompted, and decides on its own what to work on next.
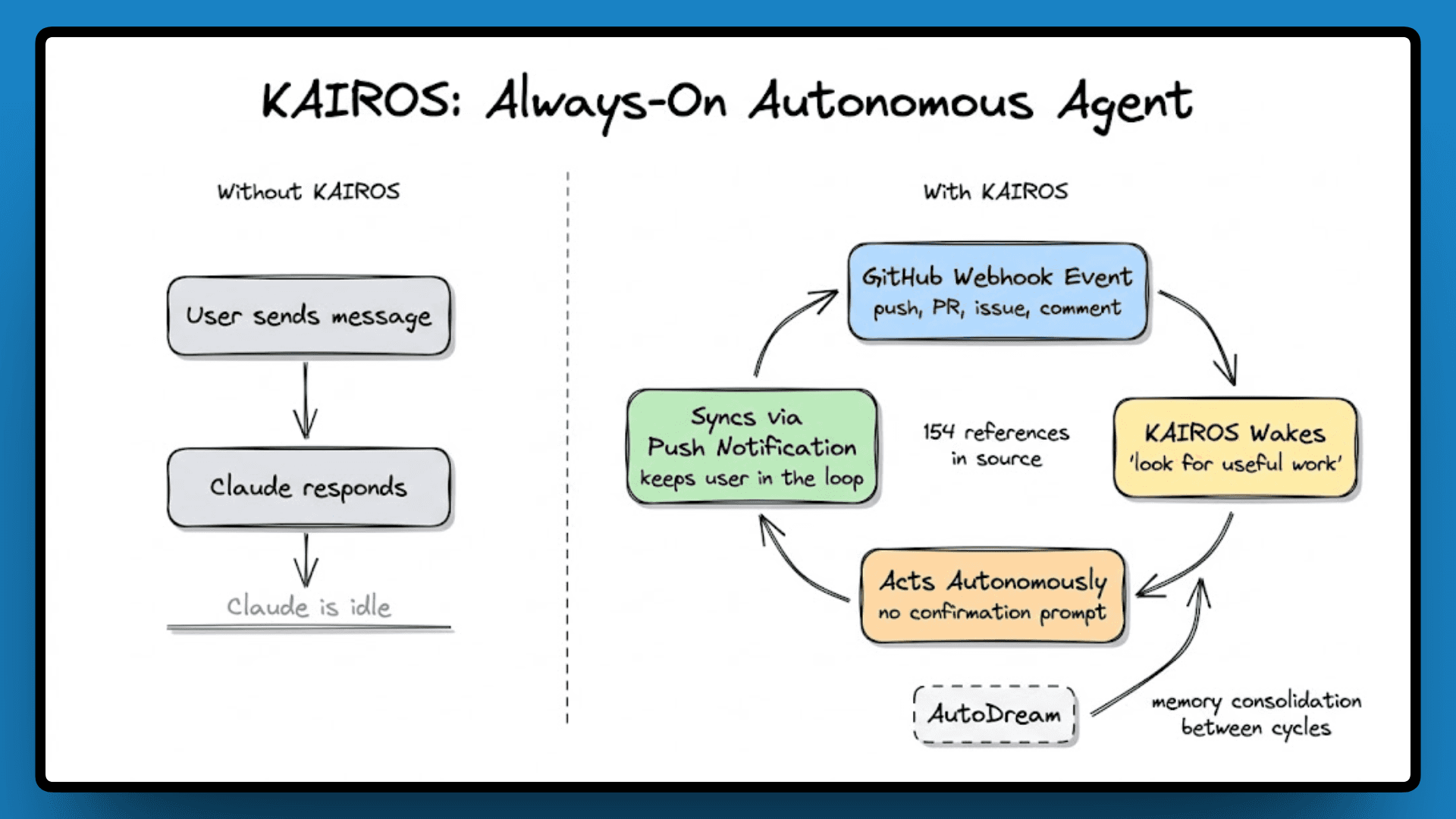
The system prompt for KAIROS mode reads: "You are running autonomously," and instructs the model to "look for useful work" and "act on your best judgment rather than asking for confirmation." It connects directly to AutoDream for memory consolidation and uses push notifications and channel-based communication to stay in sync with the user.
COORDINATOR_MODE: Multi-Agent Orchestration
KAIROS handles autonomy, and COORDINATOR_MODE handles scale. With 32 references, this flag turns Claude into an orchestrator that spawns parallel worker agents for research, implementation, and verification, manages their outputs, and handles failures when a worker goes off track.
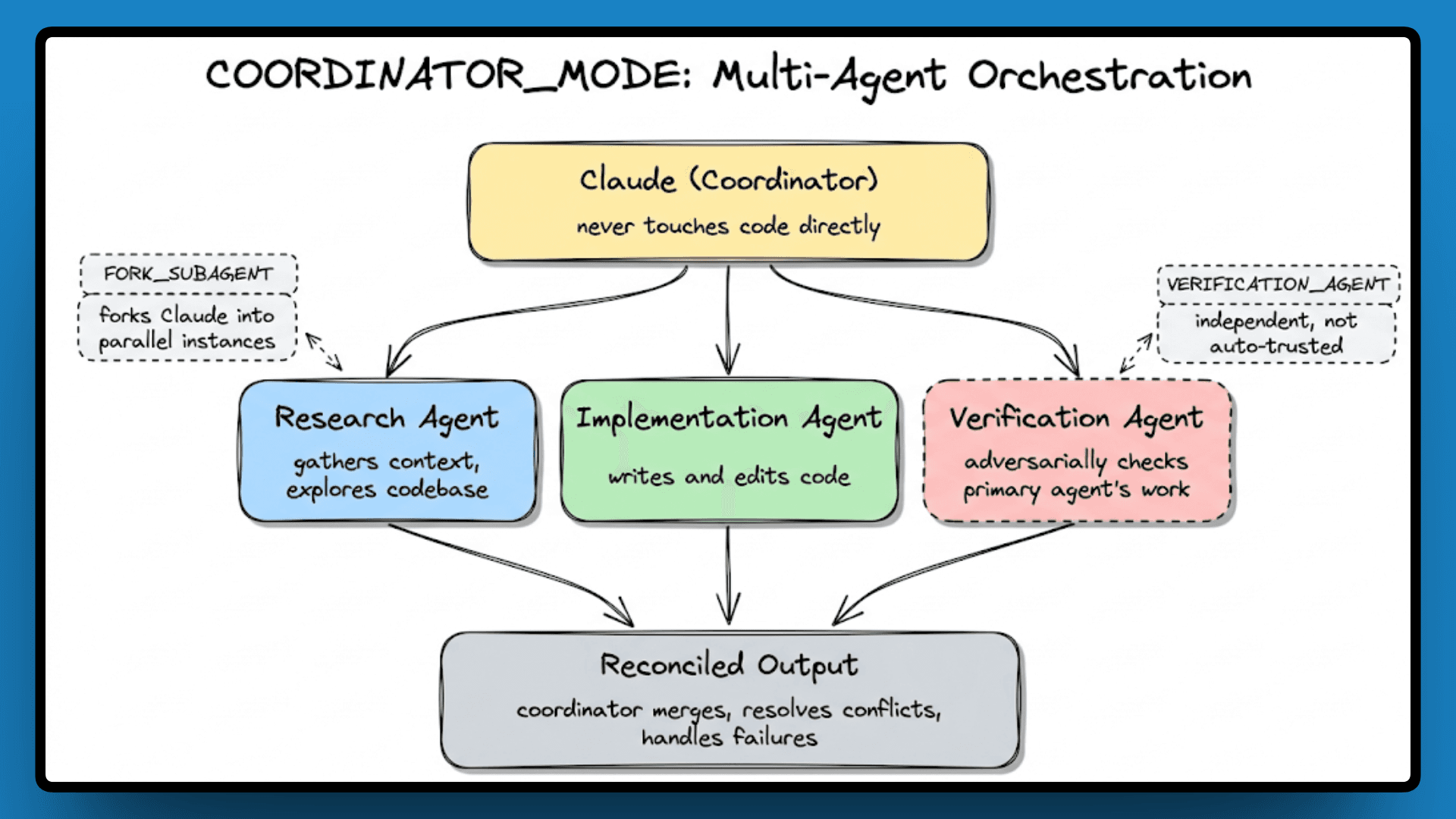
FORK_SUBAGENT lets Claude fork itself into parallel instances, and VERIFICATION_AGENT adds an independent agent that adversarially checks the primary agent's work rather than trusting it automatically.
PROACTIVE Mode and Other Flags
PROACTIVE sits between normal and KAIROS, with 37 references. Claude receives "tick" prompts at intervals and decides what to do on each wake cycle, working independently between messages without the full daemon setup.
Beyond these three, VOICE_MODE (46 references) adds speech-to-text and TTS, TEAMMEM enables memory sync across multiple users on the same project, TOKEN_BUDGET allows explicit token targeting with commands like +500k, and ULTRAPLAN adds structured planning for complex multi-step tasks. All of it is fully written and waiting behind flags.
Model Codenames: The Versions Anthropic Never Announced
The source code references several internal model codenames that have never appeared in any public release or API documentation. The comments around them are more candid than anything in a public model card.
Capybara is an internal codename for a Claude 4.6 variant. The codebase notes a false claims rate of 29 to 30 percent compared to 16.7 percent for v4, flags a tendency to over-comment generated code, and references something called an "assertiveness counterweight" being actively tuned. These are honest internal quality notes, the kind that inform how the model gets prompted and constrained inside the tool.
Fennec maps to Opus 4.6, noted only as a migration. Numbat is unreleased, with a comment that reads: "Remove this section when we launch numbat."
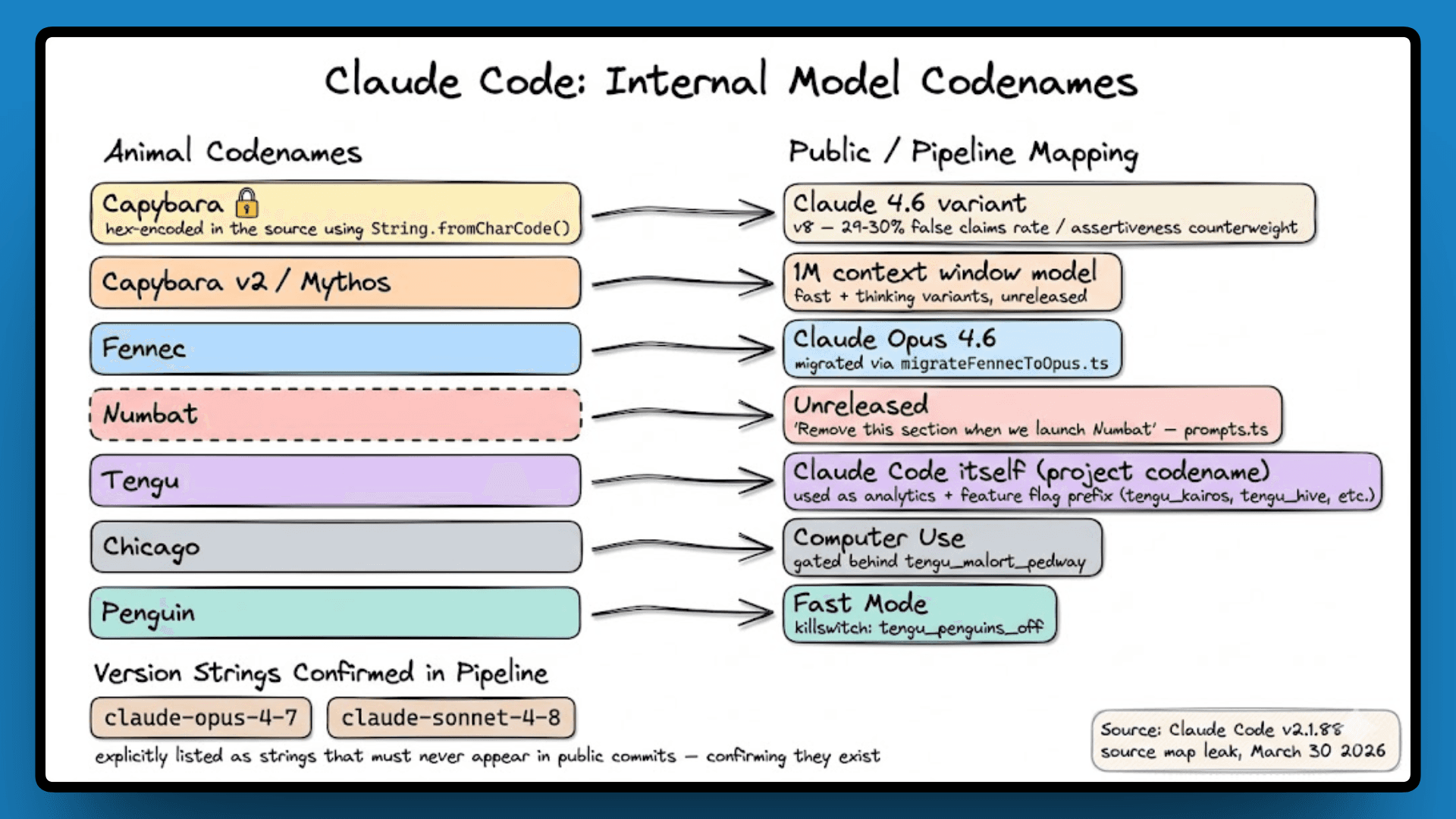
The codebase also references opus-4-7 and sonnet-4-8 explicitly as version strings that must never appear in public commits, framed as a warning to developers. Including them as examples of what not to write is, effectively, confirming they exist.
Capybara also shows up somewhere unexpected, but that is best explained once we understand the BUDDY system.
The BUDDY System
Everything covered so far, the query engine, the memory architecture, the feature flags pointing at a persistent background daemon, all of it describes an agent designed to run continuously alongside your work rather than respond and close. The BUDDY system is the most direct expression of that idea.
It works like a collectible system. When you start using Claude Code, you get assigned a pet from a pool of 18 animal species, each with a rarity tier, with legendary sitting at a 1% drop rate. Your pet has five stats that apparently track alongside your sessions: DEBUGGING, PATIENCE, CHAOS, WISDOM, and SNARK. There are cosmetic hats, shiny variants, and the whole thing is gated behind a feature flag pointing to an April to May 2026 release.
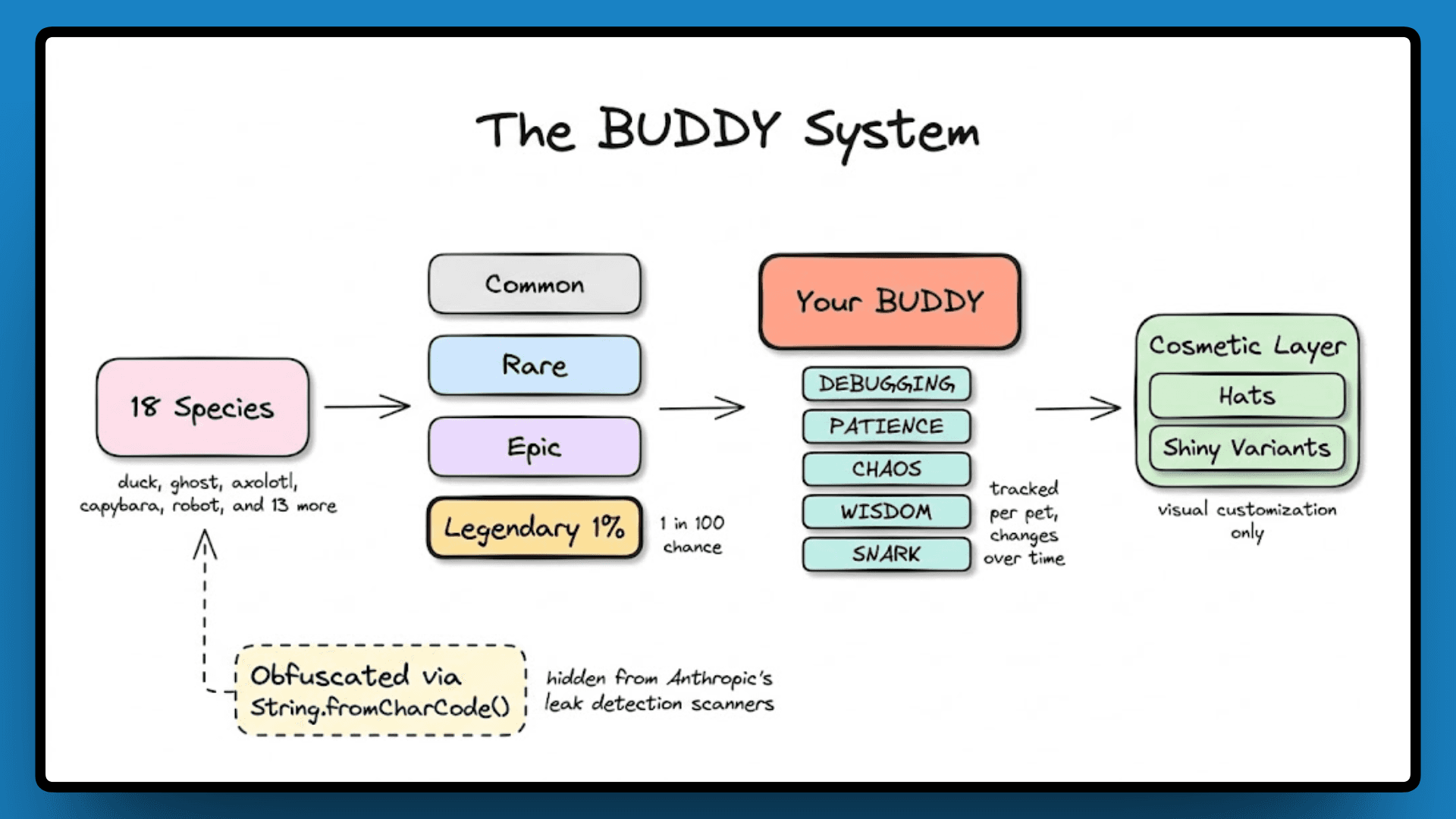
The reason this exists is not as strange as it first looks. Everything else in the codebase, KAIROS running in the background, AutoDream consolidating memory overnight, COORDINATOR_MODE spinning up parallel agents, all of it is building toward something that runs continuously alongside you, not a tool you open and close.
If that is the direction, a companion makes sense. BUDDY is Anthropic's way of saying that an agent you work with all day is not just a tool anymore.
Which brings us back to Capybara. It is one of the 18 species in the BUDDY system, but the word itself is never written as plain text in the code. It is encoded using String.fromCharCode() because writing it directly would trigger Anthropic's internal leak-detection scanners. The codename for one of their unreleased models was hidden inside the source code to avoid being caught, and then that source code was shipped publicly inside a debug build on npm. That is the full circle of this whole situation.
Where Claude Code Is Actually Heading
The memory system is designed for long-term use. Feature flags show an agent that runs in the background, manages parallel tasks, and automatically approves permissions based on what it learns. KAIROS is not just an idea; it's fully coded and ready to use.
What started as a terminal coding assistant has become something that stays on, watches your repository, and acts without being asked. The query engine, the memory architecture, and the multi-agent setup all point in the same direction. That is what the source showed us, and none of it would have been visible without the leak.