


Claude Opus 4.6 vs Gemini 3 Pro: A Practical Comparison for Developers
TL;DR
Claude Opus 4.6 is better suited for workflows that require structured reasoning, consistent outputs, and a reliability-first approach to decision-making.
Gemini 3 Pro is a stronger fit for execution-driven workflows that benefit from faster responses, agent-style task handling, and multimodal capabilities.
The right choice depends on how you balance reasoning depth versus execution speed in real-world tasks.
Introduction
Claude Opus 4.6 has just been released, bringing noticeable improvements in reasoning, long-context handling, and agentic workflows. Around the same time, Gemini 3 Pro has emerged as Google’s most capable model so far, with strong performance in reasoning, multimodal understanding, and tool-driven execution. W
With both models targeting complex, real-world tasks rather than simple prompt responses, it makes sense to look at how they compare in practice.
In this article, I explore the differences between Claude Opus 4.6 and Gemini 3 Pro, focusing on their capabilities, performance, and how they behave across real developer scenarios.
Brief Overview: Claude Opus 4.6
Claude Opus 4.6 is Anthropic’s latest flagship model, designed for reasoning-heavy, long-context, and reliability-focused workflows. It is aimed at developers, analysts, and teams that value clarity, structured outputs, and careful decision-making over raw speed.
What’s New in Claude Opus 4.6
Stronger reasoning and planning: Improved step-by-step reasoning with better judgment on ambiguous or complex problems.
Long-context support (up to 1M tokens, beta): Handles very large documents and sustained conversations with less context drift.
Adaptive thinking and effort controls: Developers can tune how deeply the model reasons, balancing cost, latency, and quality.
Improved coding quality and reviews: Better at working within large codebases, reviewing code, and catching its own mistakes.
Structured and reliable outputs: Excels at producing clean tables, reports, and well-organized content for knowledge work.
Strong safety and alignment focus: Maintains low rates of misaligned behavior while reducing unnecessary refusals.
Brief Overview: Gemini 3 Pro
Gemini 3 Pro was released by Google DeepMind as its most advanced model to date, positioned for complex reasoning, multimodal understanding, and agentic workflows. It is built for developers and teams working on large-scale, long-context, and production-oriented AI systems, especially within the Google ecosystem.

Features of Gemini 3 Pro
State-of-the-art reasoning performance: Leads on several reasoning benchmarks, including Humanity’s Last Exam, highlighting strong problem-solving and planning abilities.
Long-context support up to 1M tokens: Designed to handle very large documents and extended workflows, with strong long-context retrieval performance.
Advanced multimodal capabilities: Natively understands and reasons across text, images, video, audio, PDFs, and code.
Agent-ready design with strong tool use: Supports function calling, structured outputs, search, and code execution, enabling multi-step and parallel agentic tasks.
Strong coding and UI understanding: Performs well on agentic coding benchmarks and screen understanding tasks, making it suitable for front-end and interactive workflows.
Deep ecosystem integration: Available across the Gemini app, Google AI Studio, Gemini API, and Google Cloud / Vertex AI, making deployment easier for teams already on Google infrastructure.
Benchmark Comparison: Claude Opus 4.6 vs Gemini 3 Pro
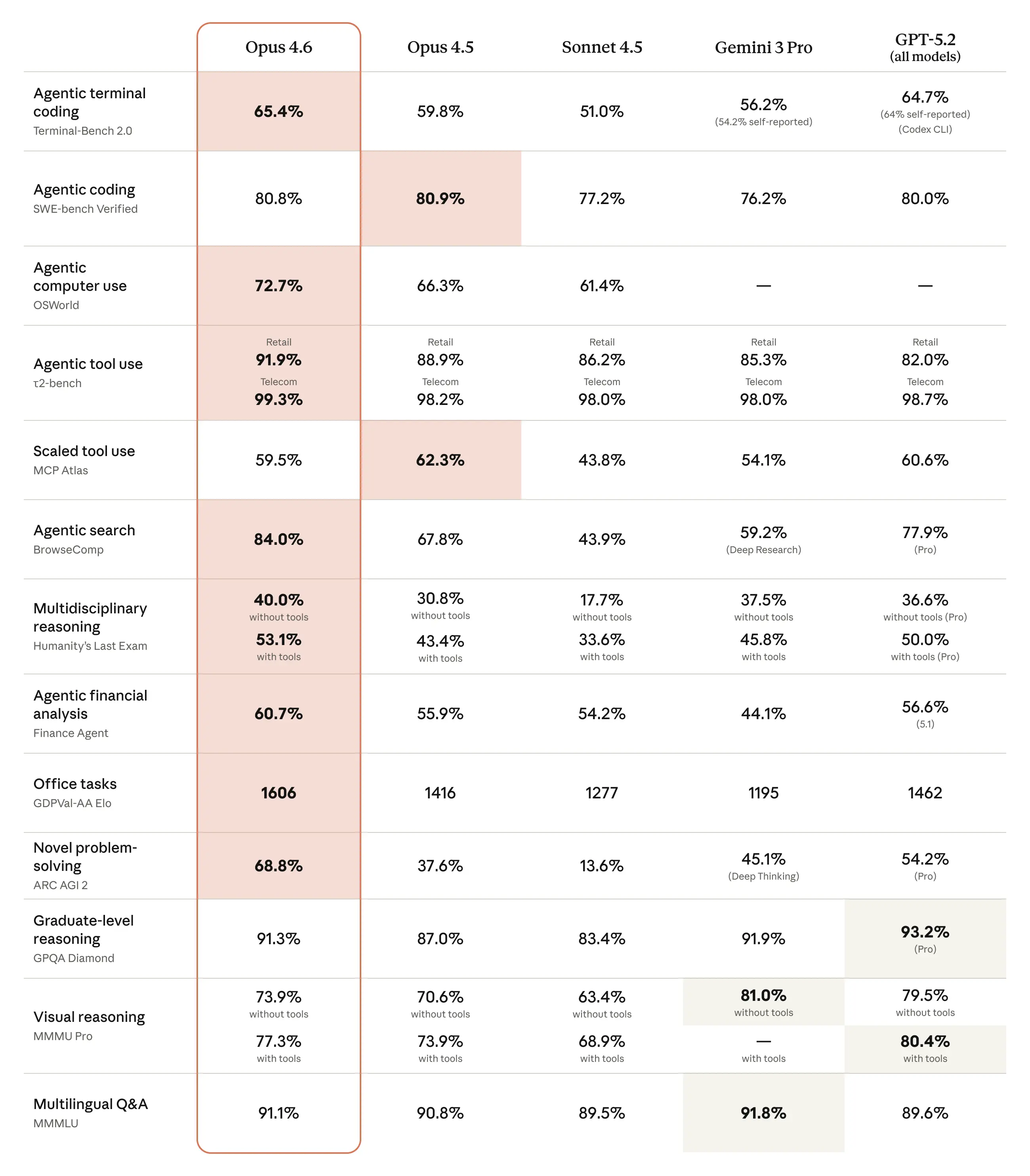
Below are the detailed benchmarks of each model:
{kind=link}
Benchmark | What it Measures | Claude Opus 4.6 | Gemini 3 Pro |
|---|---|---|---|
Terminal-Bench 2.0 | Agentic terminal coding and CLI task execution | 65.4% | 56.2% (54.2% self-reported) |
SWE-Bench Verified | Real-world software engineering tasks | 80.8% | 76.2% |
τ2-bench | Agentic tool use across domains | 91.9% (Retail)99.3% (Telecom) | 85.3% (Retail)98.0% (Telecom) |
BrowseComp | Agentic search and information retrieval | 84.0% | 59.2% |
Humanity’s Last Exam (no tools) | Multidisciplinary reasoning | 40.0% | 37.5% |
Humanity’s Last Exam (with tools) | Tool-augmented reasoning | 53.1% | 45.8% |
Finance Agent | Agentic financial reasoning | 60.7% | 44.1% |
GDPval-AA (Elo) | Office and knowledge-work tasks | 1606 | 1195 |
ARC-AGI-2 | Novel problem-solving | 68.8% | 45.1% |
GPQA Diamond | Graduate-level scientific reasoning | 91.3% | 91.9% |
MMMU-Pro (no tools) | Visual and multimodal reasoning | 73.9% | 81.0% |
MMMLU | Multilingual Q&A | 91.1% | 91.8% |
Comparing Reasoning & Intelligence Capabilities
To compare the intelligence and reasoning capabilities of Claude Opus 4.6 and Gemini 3 Pro, I used a realistic decision-making scenario rather than abstract logic puzzles.
The goal of this task is to observe how each model reasons through constraints, evaluates trade-offs, and structures a practical plan when there is no single correct answer.
Prompt (Use for Both Models)
You are advising a mid-sized company that is planning to adopt AI across its operations over the next 12 months.
Constraints:
Limited budget
Small engineering team
High expectations from leadership
Concerns around data security and reliability
Tasks:
Identify the top 3 areas where AI adoption would deliver the highest impact.
Explain the trade-offs and risks for each area.
Propose a phased rollout plan over 12 months.
Highlight one common mistake companies make in similar situations and how to avoid it.
Focus on clear reasoning, realistic assumptions, and structured thinking. Avoid buzzwords.
Claude Opus 4.6: Reasoning Task Output
Using the prompt above, I ran the reasoning task on Claude Opus 4.6 to evaluate how it structures decisions, handles trade-offs, and presents a phased, risk-aware plan under realistic constraints.
The result was:
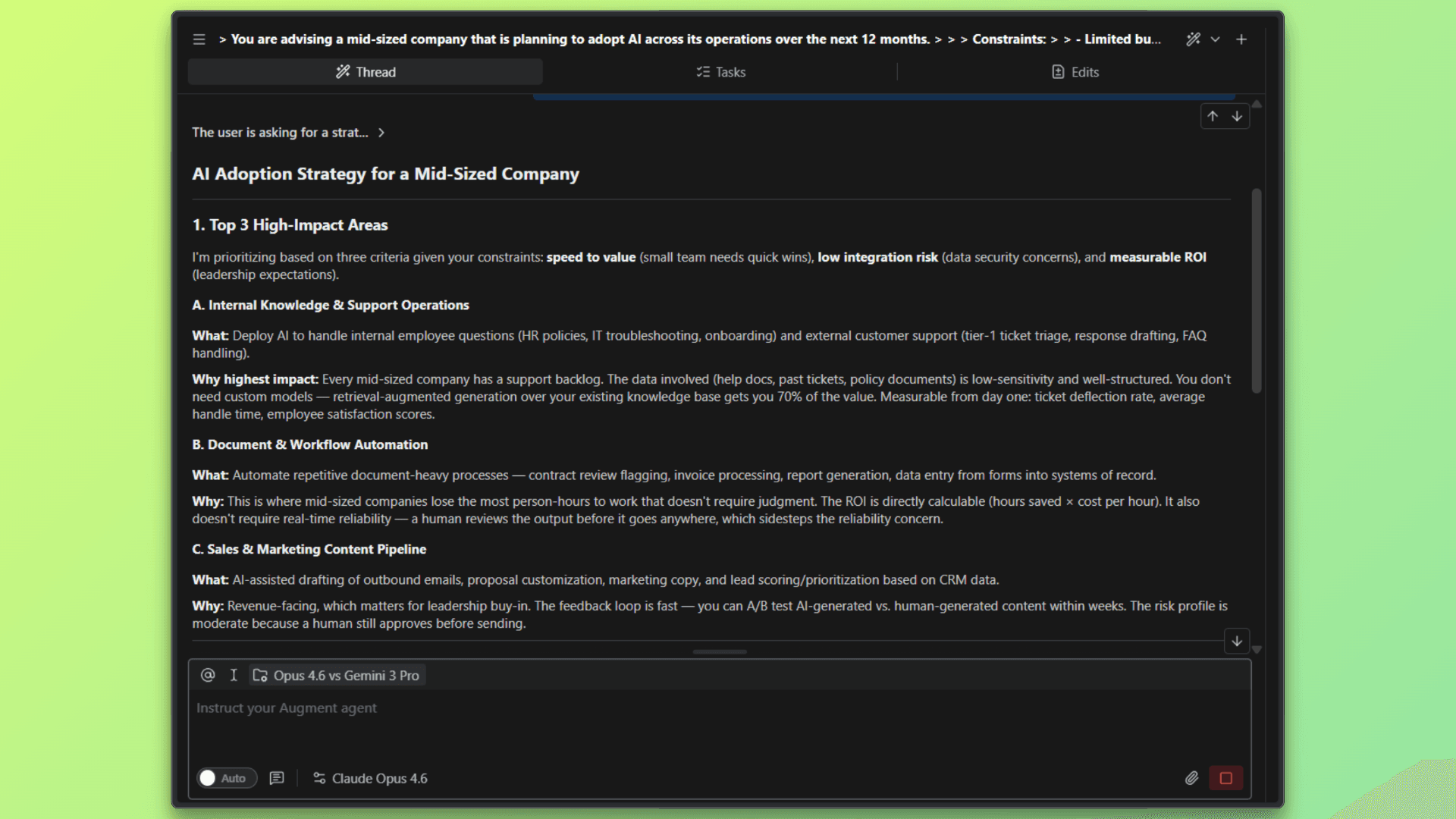
Claude Opus 4.6 approached the problem in a deliberate and structured manner, clearly framing its recommendations around constraints like budget, security, and speed to value. The response emphasized practical prioritization, measurable ROI, and risk mitigation, with each decision explicitly justified.
Although it took around 10 seconds to complete, the output felt carefully reasoned and conservative, reflecting a preference for clarity and long-term reliability over speed. Overall, Opus 4.6 demonstrated strong strategic thinking, with an emphasis on structured reasoning and cautious execution.
Gemini 3 Pro: Reasoning Task Output
Using the same prompt, I ran the reasoning task on Gemini 3 Pro to assess its approach to prioritization, decision clarity, and how directly it moves from constraints to recommendations.
The result was:
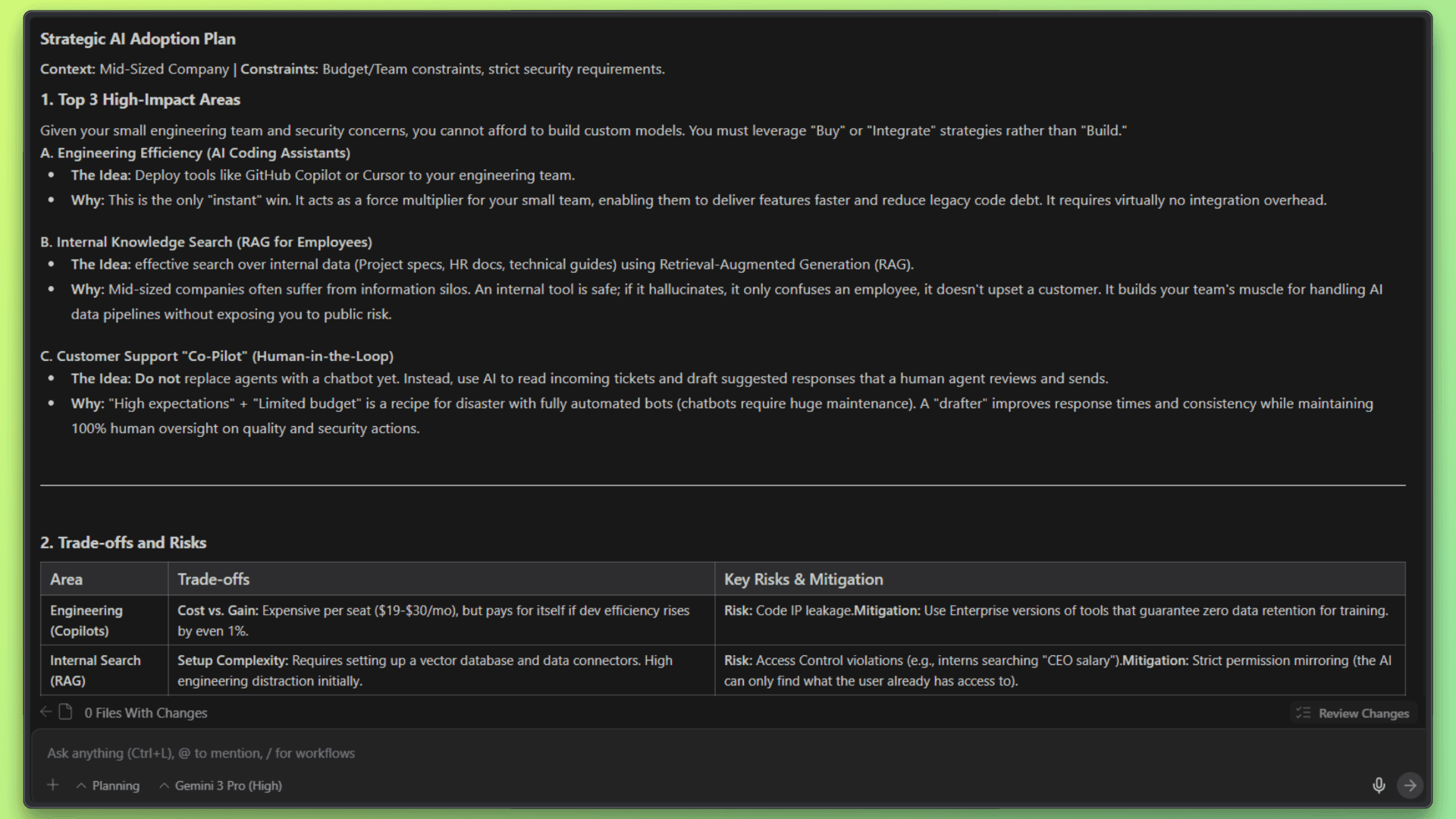
Gemini 3 Pro completed the task faster, with visible reasoning in around 6 seconds, and delivered a more direct, assertive strategy. The output focused on decisive recommendations, clear trade-offs, and execution-first guidance, especially around tooling and integration choices.
Compared to Opus, Gemini’s reasoning was more concise and action-oriented, favoring momentum and speed over detailed justification. This made the response feel efficient and pragmatic, particularly well-suited for teams that value quick decision-making and rapid alignment.
Coding Performance Comparison
To understand how Claude Opus 4.6 and Gemini 3 Pro perform in practical front-end work, I compared them on a simple but representative web development task: building a SaaS landing page from scratch.
This task helps surface differences in coding style, UI sensibility, and how much guidance each model needs to reach a usable result.
Prompt (Used for Both Models)
Build a responsive landing page for a SaaS product called FinTrack, a simple financial management tool for small and medium businesses.
Requirements:
Hero section with headline, subtext, and primary CTA
Features section (3–4 features)
Simple pricing section
Testimonial or trust section
Footer with basic links
Use a modern, clean design with sensible defaults for spacing, typography, and layout.
Structure the code clearly using reusable components.
Include minimal styling and avoid over-engineering.
Opus 4.6 Results - Landing Page Generation
The landing page codebase generated by Claude Opus 4.6 using the above prompt can be seen here.
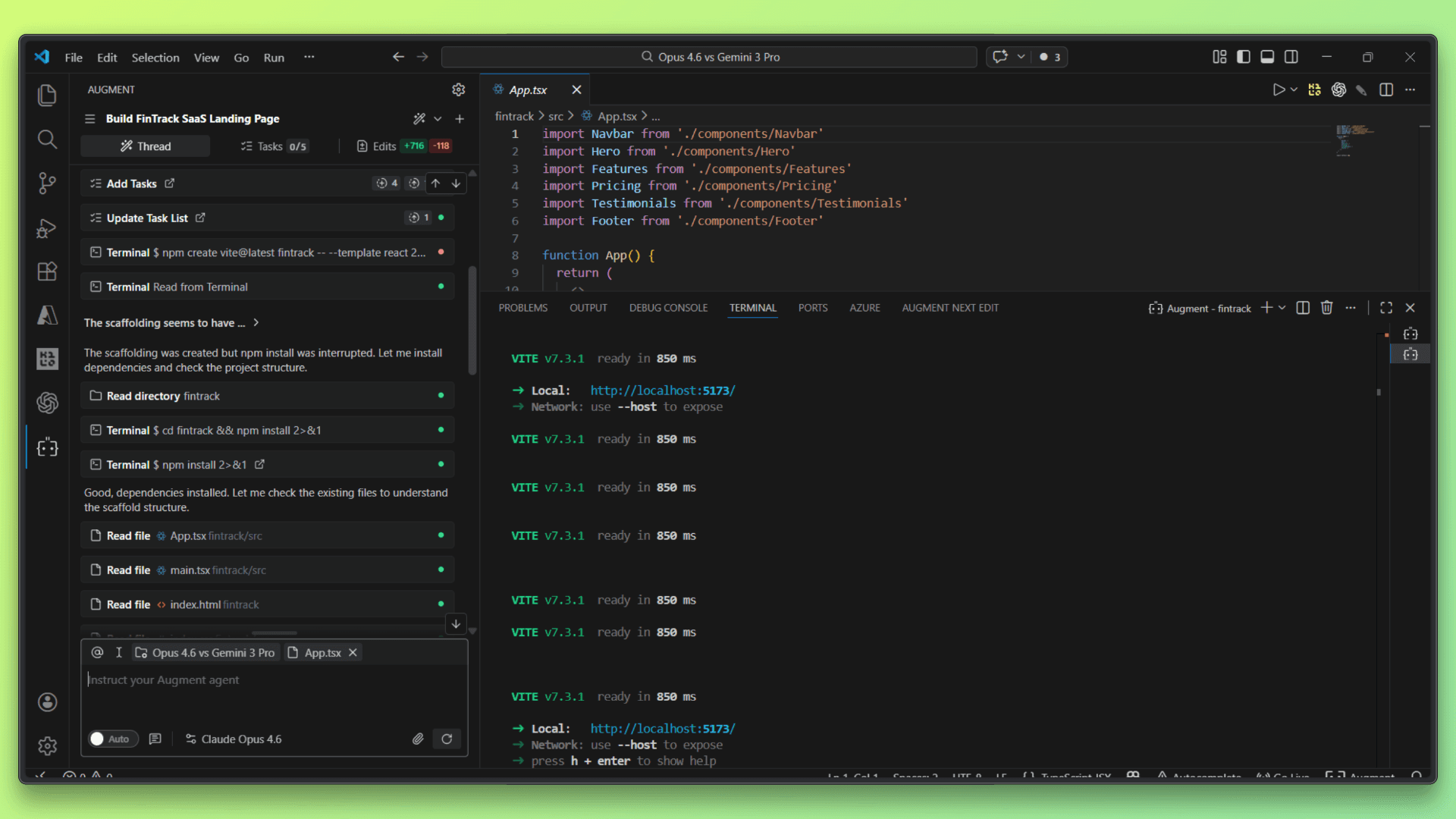
After running the project, the result was:
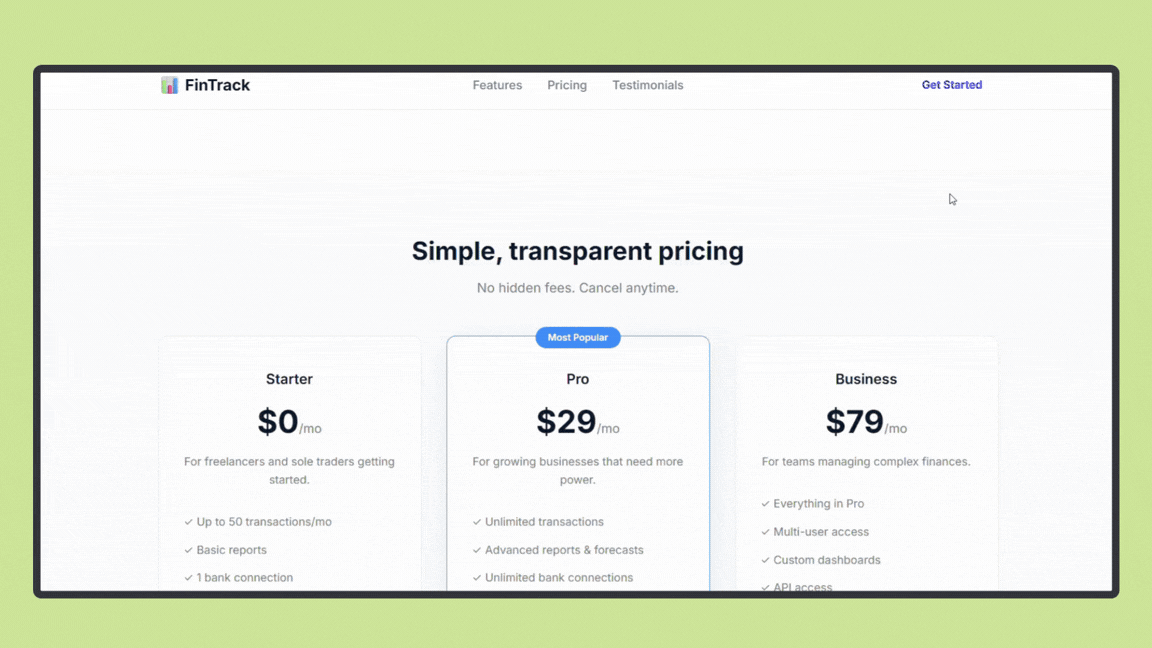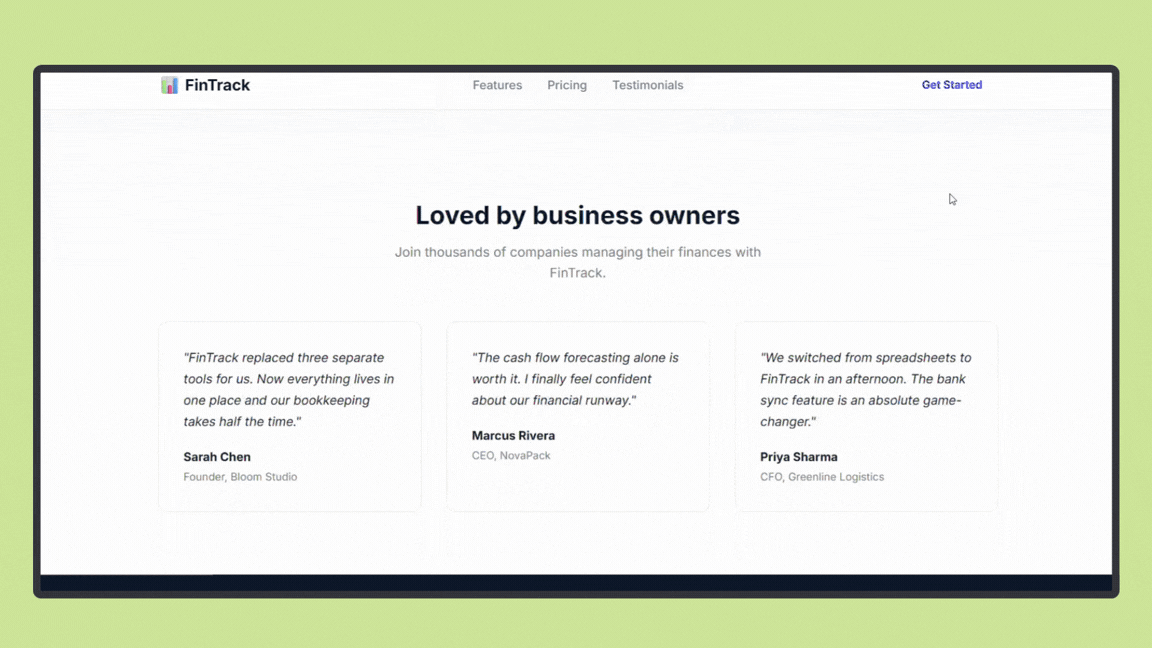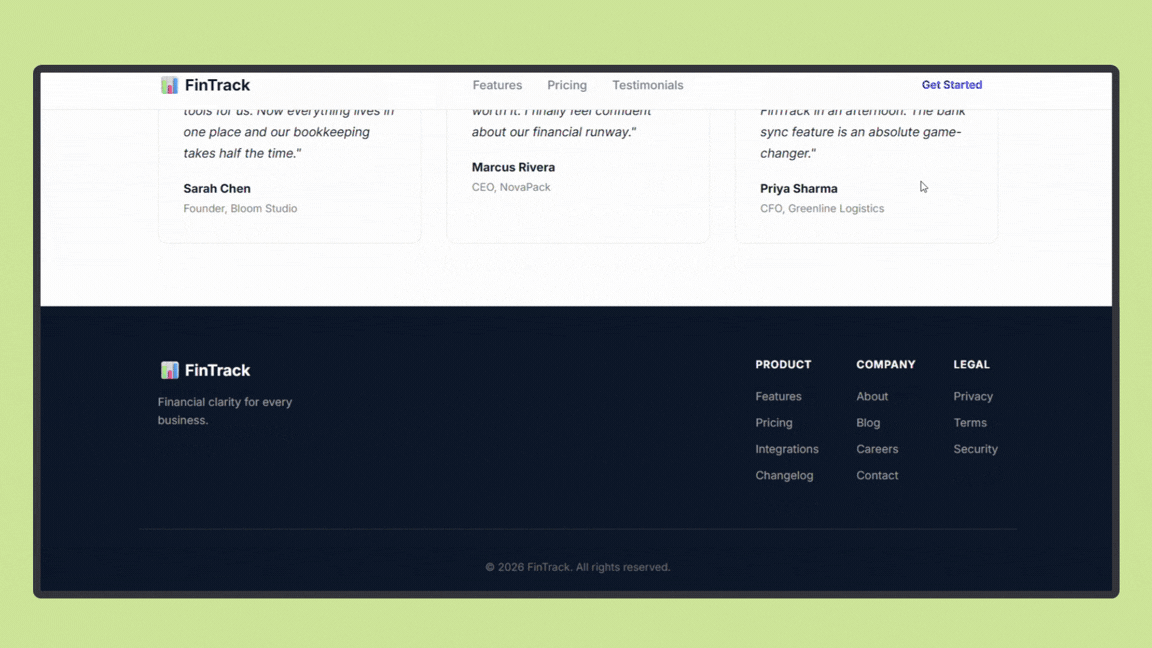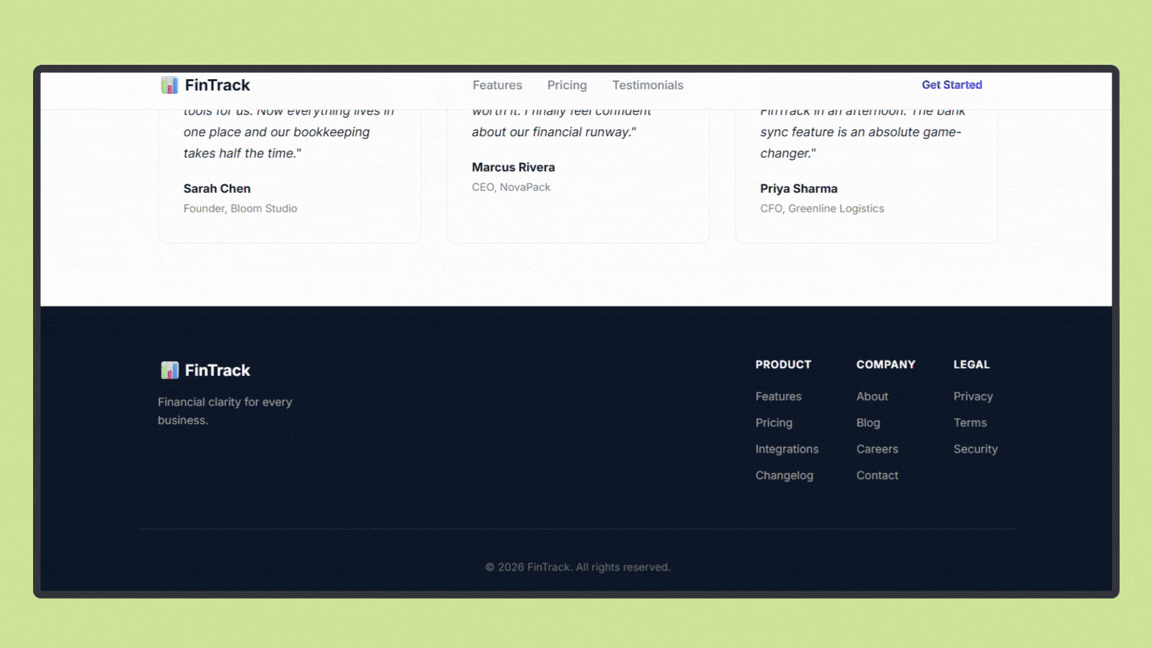
Claude Opus 4.6 produced a clean, well-structured landing page with sensible layout decisions, clear hierarchy, and consistent spacing across sections. The output focused on clarity and balance rather than visual experimentation, resulting in a design that feels production-ready and easy to extend.
Over the course of around 12 minutes, including user feedback and small corrections, the model iterated carefully on copy, layout, and component structure.
Overall, the experience reflected a deliberate, quality-first approach, with more time spent refining structure and consistency than rushing to a final result.
Gemini 3 Pro Results - Landing Page Generation
The landing page codebase generated by Gemini 3 Pro using the same prompt can be seen here.
After running the project, the result was:
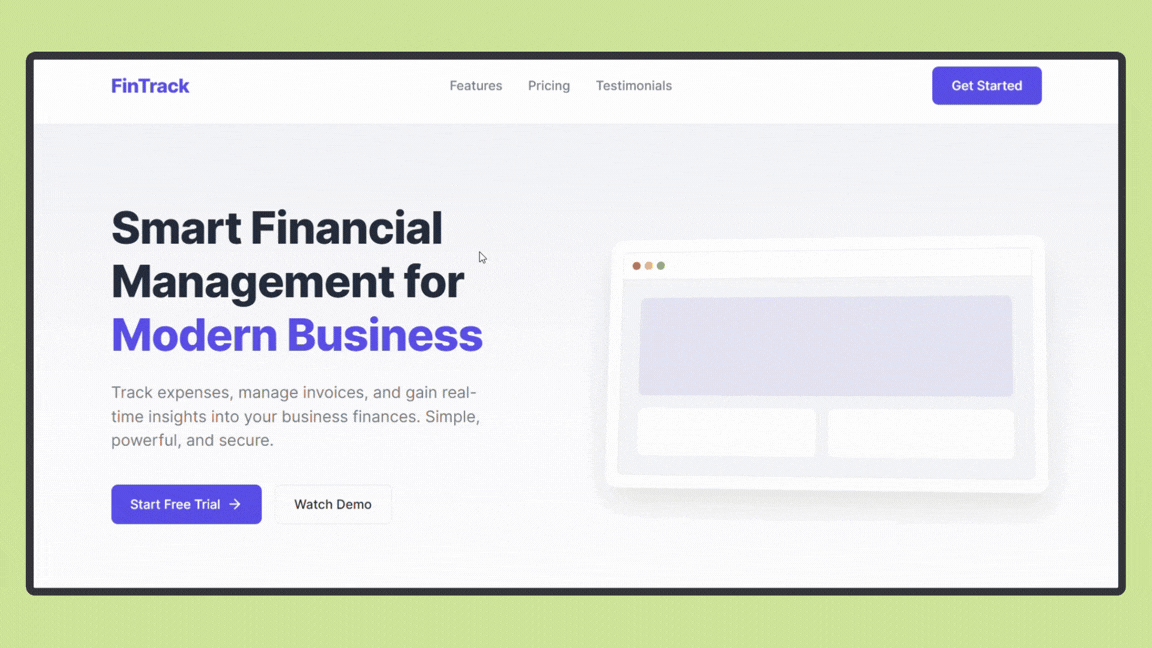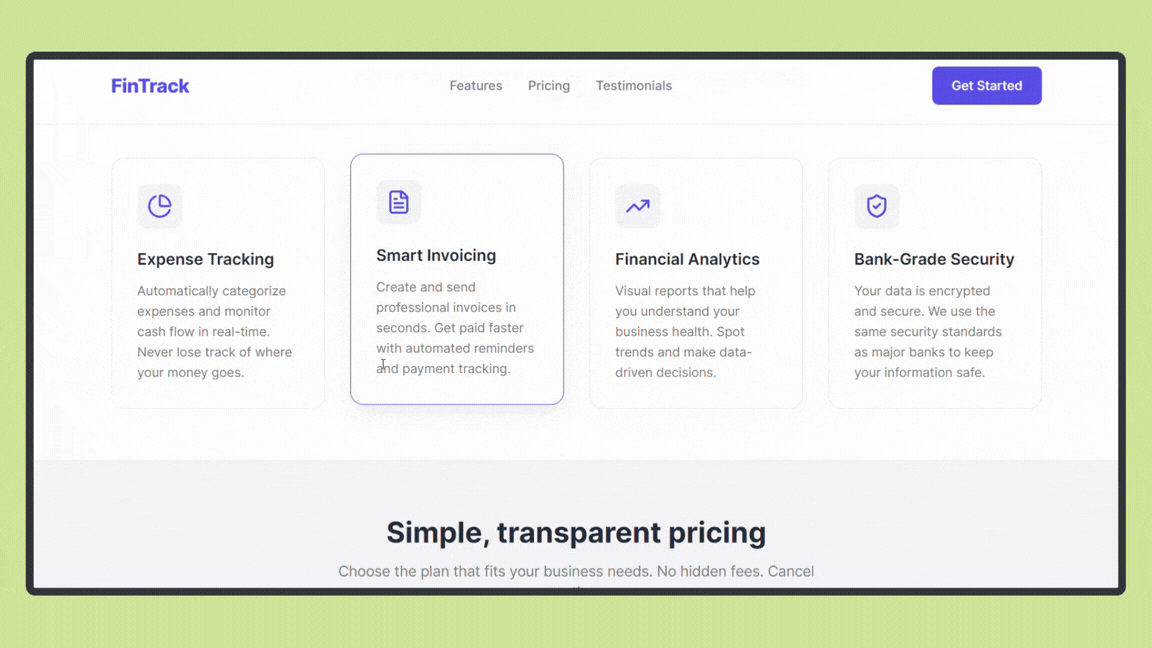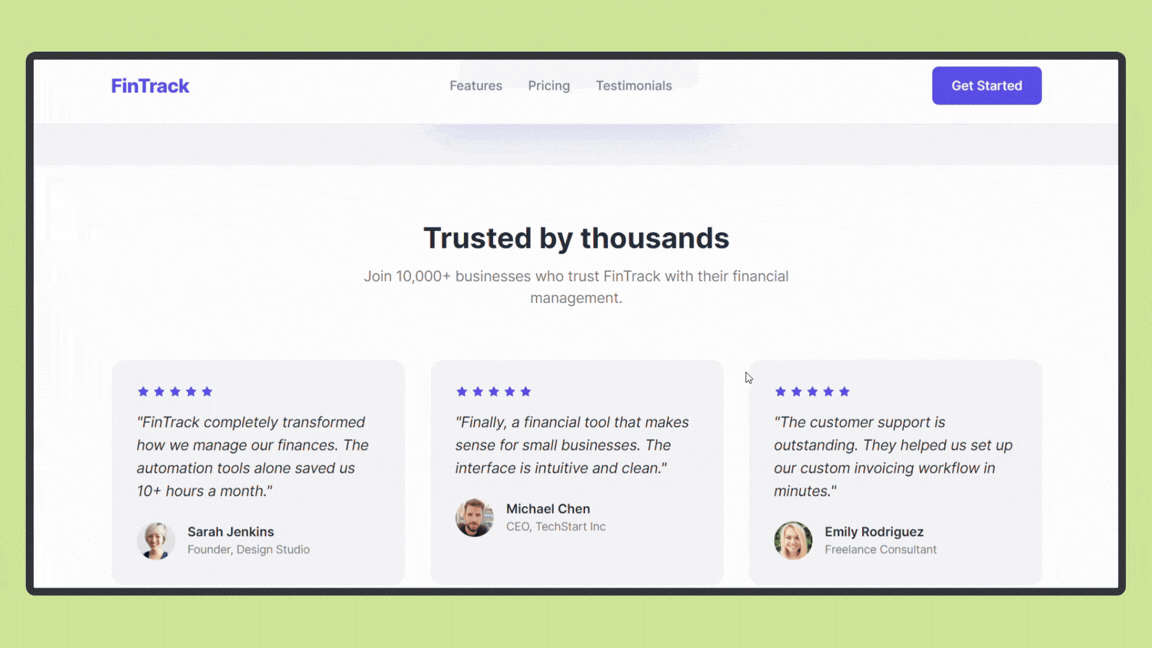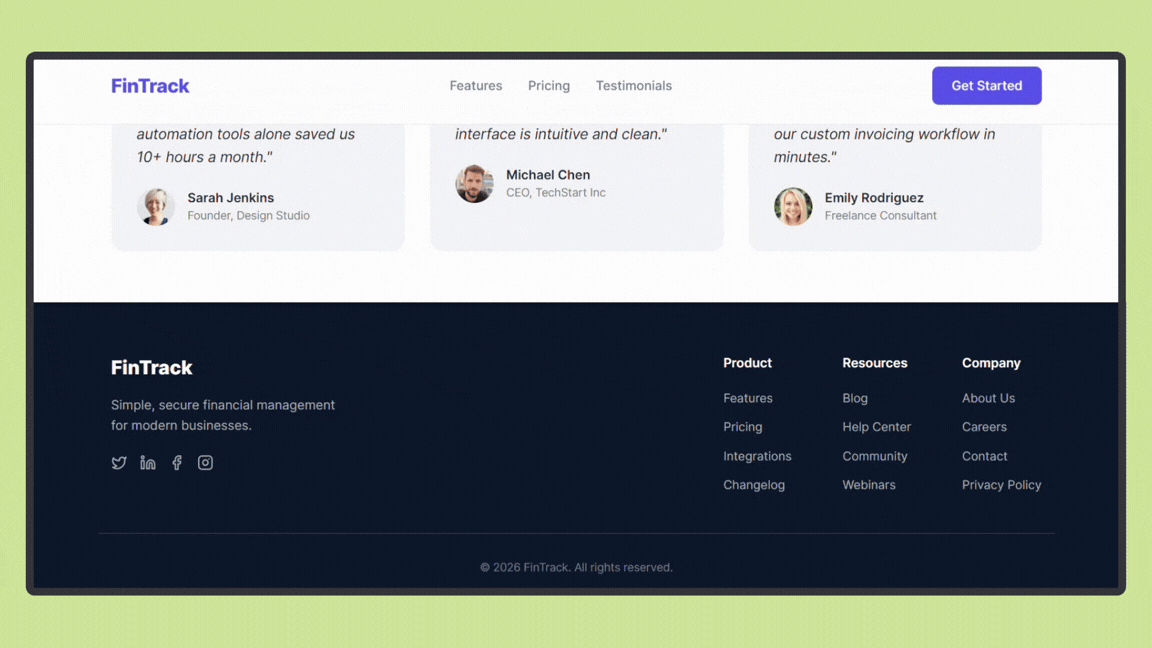
Gemini 3 Pro generated a visually polished landing page with stronger emphasis on interactive components and UI elements. The layout felt more dynamic, with clear call-to-action placement and better use of visual contrast to guide attention.
The task took around 13 minutes, including iterations and minor refinements, as the model explored richer UI patterns and component behavior.
Overall, Gemini 3 Pro leaned toward a more expressive, front-end–focused approach, prioritizing interactivity and visual appeal alongside functional structure.
Comparing Agentic & Tool-Calling Workflows
Both Claude Opus 4.6 and Gemini 3 Pro are designed to operate beyond single-turn prompts, but they differ in how they plan and execute agent-style workflows. Claude Opus 4.6 tends to approach multi-step tasks cautiously, breaking work into well-defined phases and favoring human-in-the-loop checkpoints. Its tool use is deliberate, with a clear emphasis on correctness, safety, and controlled execution over speed.
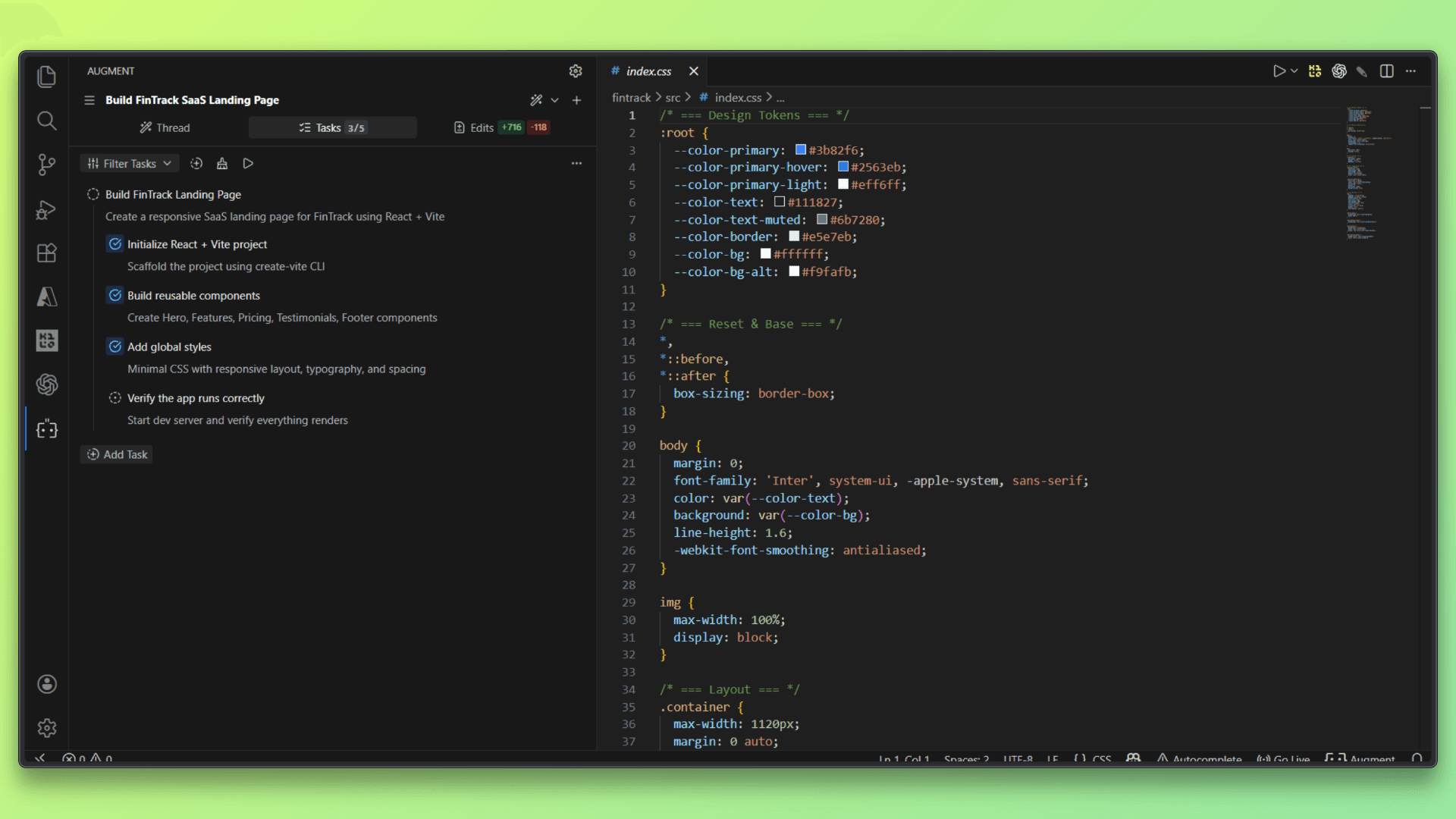
Gemini 3 Pro, by contrast, leans toward a more assertive agentic style. It plans and executes multi-step tasks more aggressively, making faster decisions about when to call tools and how to chain actions together. This results in quicker end-to-end execution, especially for workflows that involve parallel steps or rapid iteration, but with less explicit justification at each stage.
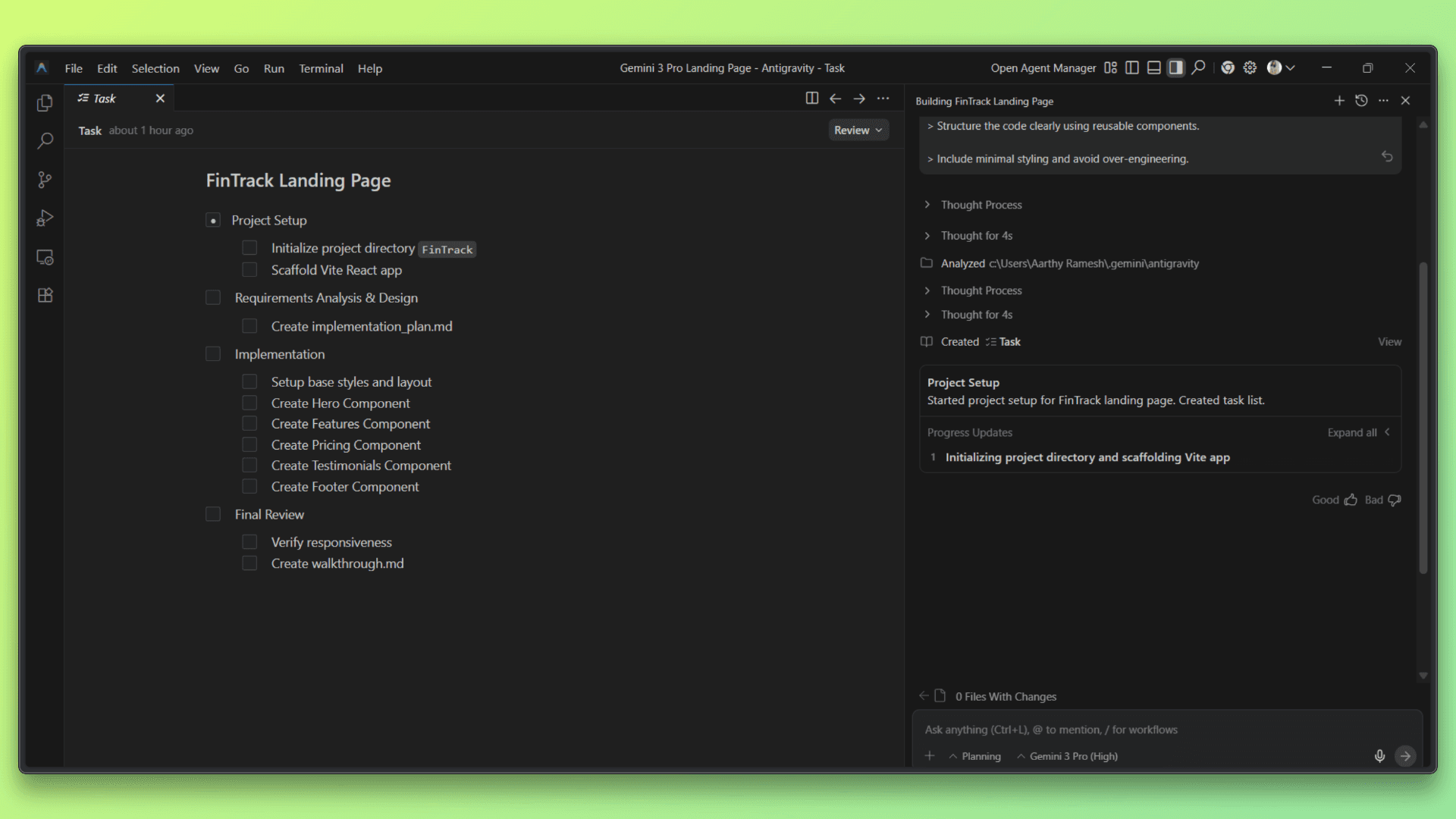
In practice, Claude Opus 4.6 fits workflows that require reliability and auditability, while Gemini 3 Pro is better suited for fast-moving, execution-driven automation.
These observations are based on hands-on task execution, iteration behavior, and response timing during the experiments shown above, rather than internal implementation details.
Final Verdict
Claude Opus 4.6 is a strong choice when reliability, structured reasoning, and controlled execution matter, especially for decision-heavy and risk-sensitive workflows. Gemini 3 Pro fits better when speed, multimodal understanding, and agentic execution across tools are the priority. Both models excel in different areas, and the right choice depends more on workflow needs than on raw capability.
If you’re looking to use these models into production-ready codebases, Entelligence.ai helps teams with AI assisted code review, insights, security, and developer workflows with minimal friction.