


Initial Impressions of GPT 5.3 Codex: Performance, Benchmarks, and Use Cases
TL;DR
GPT-5.3-Codex moves beyond code generation to reliable task execution, showing strong agentic behavior across long-running, tool-driven workflows.
It sets new highs on real-world benchmarks (56.8% SWE-Bench Pro, 77.3% Terminal-Bench, 64.7% OSWorld-Verified) while running ~25% faster and using fewer tokens.
This is the first Codex model treated as high-capability in cybersecurity, signaling a shift toward computer-native AI agents with real operational impact.
https://x.com/openai/status/2019474152743223477?s=46&t=7fUWiY3v9SZqnaWyJRZPHg
GPT 5.3 Codex has just launched, bringing stronger agentic capabilities, better execution, and improved performance across real-world developer workflows.
In this article, we will take a closer look at GPT 5.3 Codex, its performance benchmarks, and how it handles real-world developer tasks.
A Detailed Overview of GPT-5.3-Codex
GPT 5.3 Codex is the latest Codex model from OpenAI. It is designed to handle more than just writing code. The model focuses on completing tasks from start to finish, including planning, using tools, and iterating on results.
It combines the strong coding capabilities of GPT 5.2 Codex with the reasoning and professional knowledge of GPT 5.2. As a result, it performs better on longer and more complex workflows where multiple steps are involved. OpenAI also reports that GPT 5.3 Codex runs about 25% faster than earlier Codex versions, which improves responsiveness during extended sessions.
What stands out most is how the model works alongside developers. Instead of only generating code, it can move through the full development process, such as editing files, running commands, and fixing issues, while still allowing developers to guide the process at any point. This makes GPT 5.3 Codex feel closer to a practical working tool than a simple code generator.
Agentic Capabilities
Built for long tasks: GPT 5.3 Codex can handle tasks that run for hours or even days, without losing track of context or progress.
Uses real tools: It works directly with terminals, files, build tools, and browsers, instead of stopping at code suggestions.
Easy to steer while it's running: Developers can jump in at any point, ask questions, provide feedback, or change direction without restarting the task.
Handles extended projects well: The model can iterate on larger projects over time and continue making steady progress across long sessions.
Less micromanagement required: Compared to earlier Codex models, it needs fewer clarifications and less step-by-step guidance to move work forward.
Coding & Engineering Performance (Benchmarks)
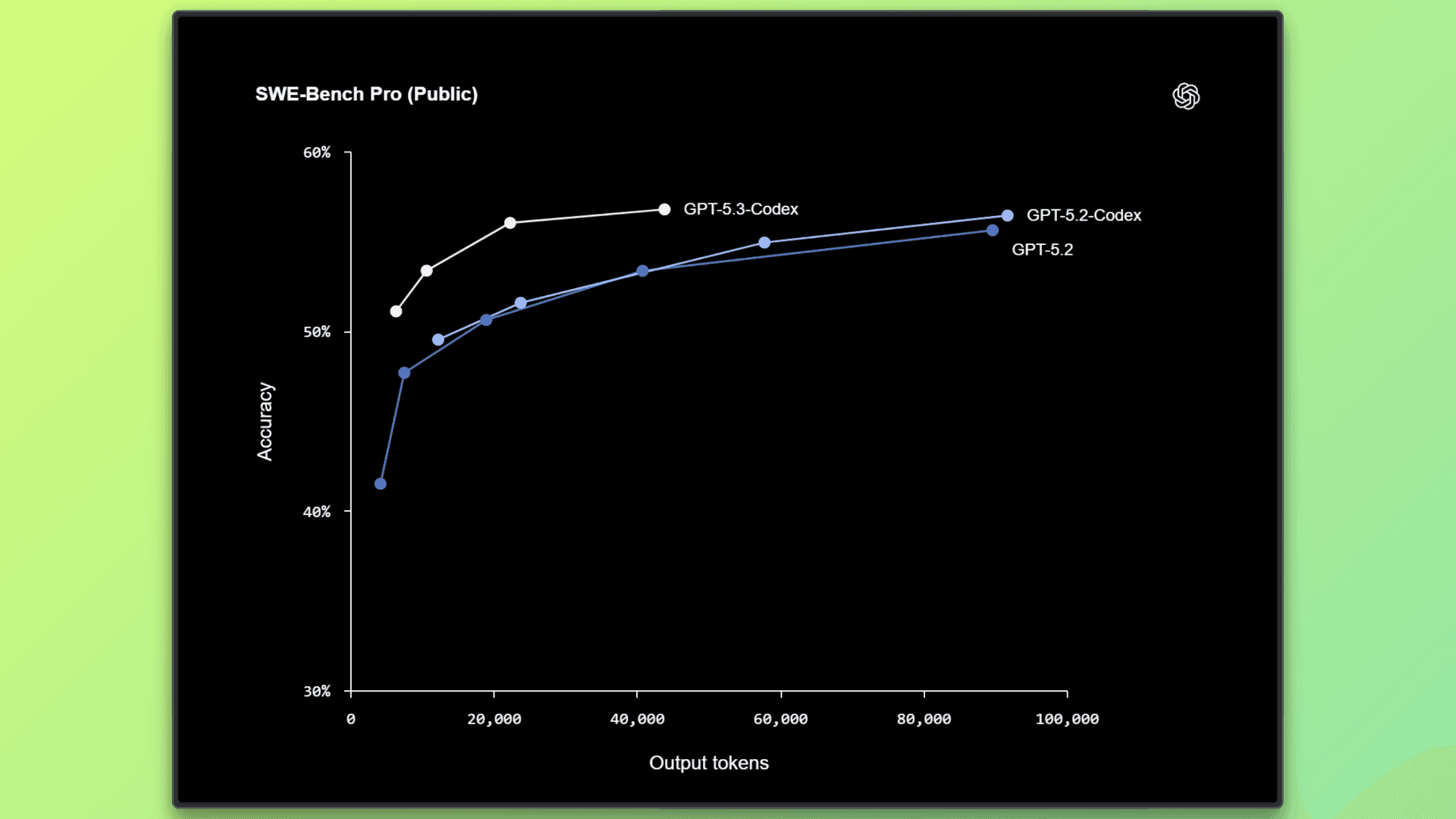
The benchmarks below highlight how GPT 5.3 Codex performs on real-world software engineering and developer workflows.
Instead of focusing on isolated code generation, these evaluations assess practical skills such as debugging, terminal use, and working with real codebases. (Read More)
Benchmark | Score | What It Measures | Why It Matters |
|---|---|---|---|
SWE-Bench Pro | 56.8% | Ability to solve real software engineering tasks from real codebases across multiple programming languages | Reflects performance on realistic engineering work such as bug fixes and feature implementation |
Terminal-Bench 2.0 | 77.3% | Effectiveness in using the command line, including running commands, debugging errors, and managing files | Shows strong improvement in practical developer workflows compared to GPT 5.2 Codex |
OSWorld Verified | 64.7% | Ability to complete tasks in a visual desktop environment using GUI interactions and file operations | Indicates credible computer use behavior rather than just code generation |
GDPval (44 occupations) | 70.9% wins or ties | Performance on real knowledge work tasks such as presentations, spreadsheets, and reports | Shows the model can handle professional tasks beyond coding |
Token Efficiency | Fewer tokens | Amount of output needed to complete tasks | Higher efficiency leads to faster responses and cleaner outputs |
Real-World Use Cases Observed
Here are a few applications where GPT-5.3 Codex stands out:
Software Engineering and DevOps
GPT 5.3 Codex is well-suited for day-to-day software engineering and DevOps workflows where tasks span multiple steps and tools. It can help implement features end-to-end by modifying code, running tests, and iterating based on results. Developers can use it to debug production issues by analyzing logs alongside source code, rather than switching contexts.
It also performs well when refactoring large or legacy codebases, where understanding structure and dependencies matters. In DevOps scenarios, it can assist with writing, fixing, and validating CI CD pipelines, infrastructure scripts, and deployment related tooling, reducing manual effort in routine engineering tasks.
Product and Web Development
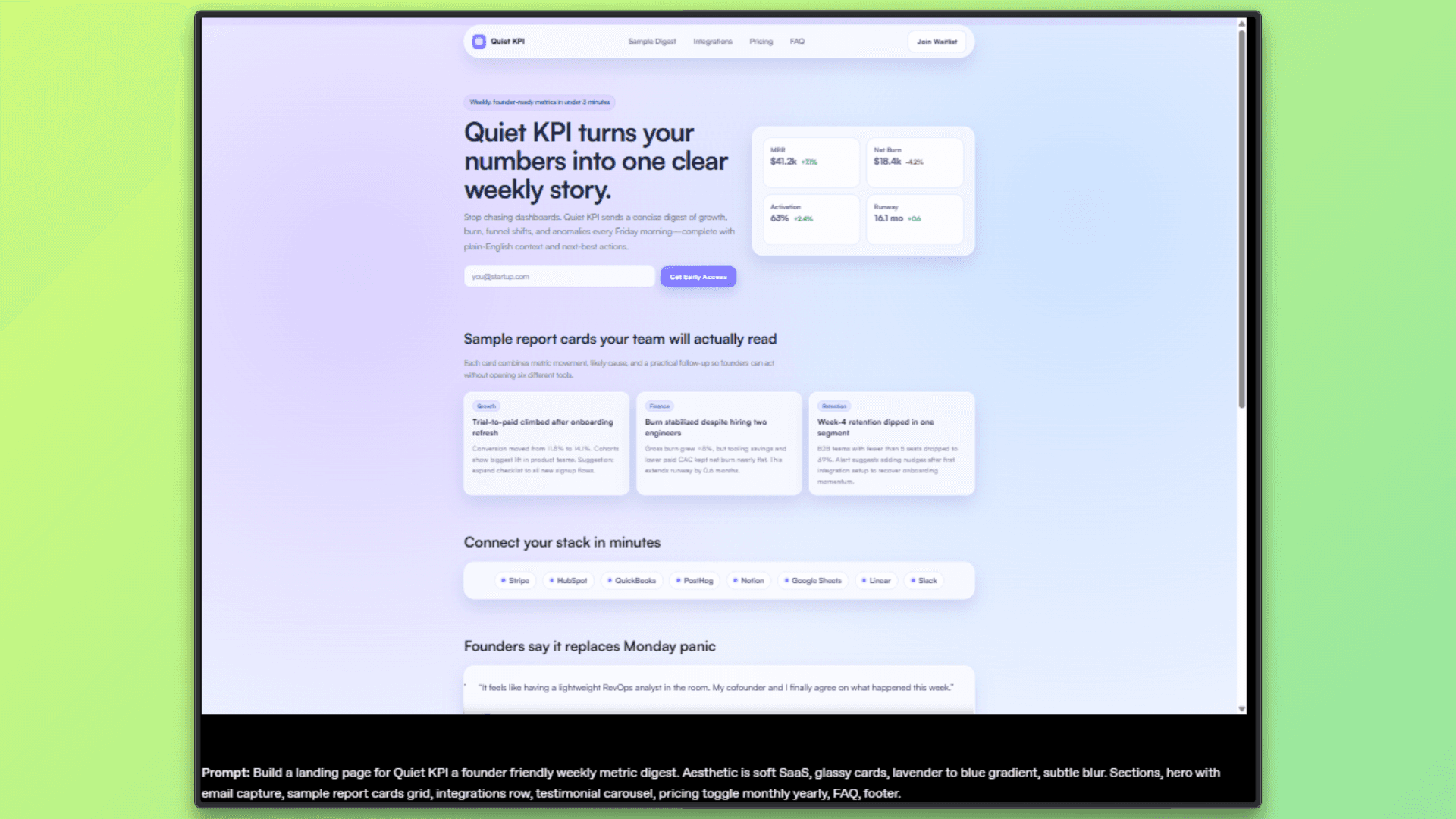
In product and web development, GPT 5.3 Codex helps move ideas into working applications more quickly. It can build full-stack applications from an initial concept and continue iterating as requirements evolve. When working on user interfaces, it tends to apply sensible defaults instead of relying on placeholders, which makes early versions feel more complete.
It is also useful for implementing common product features such as pricing logic, forms, authentication flows, and dashboards. Overall, it shortens the path from a rough idea to a functional prototype that developers can refine further.
Research and Data Work
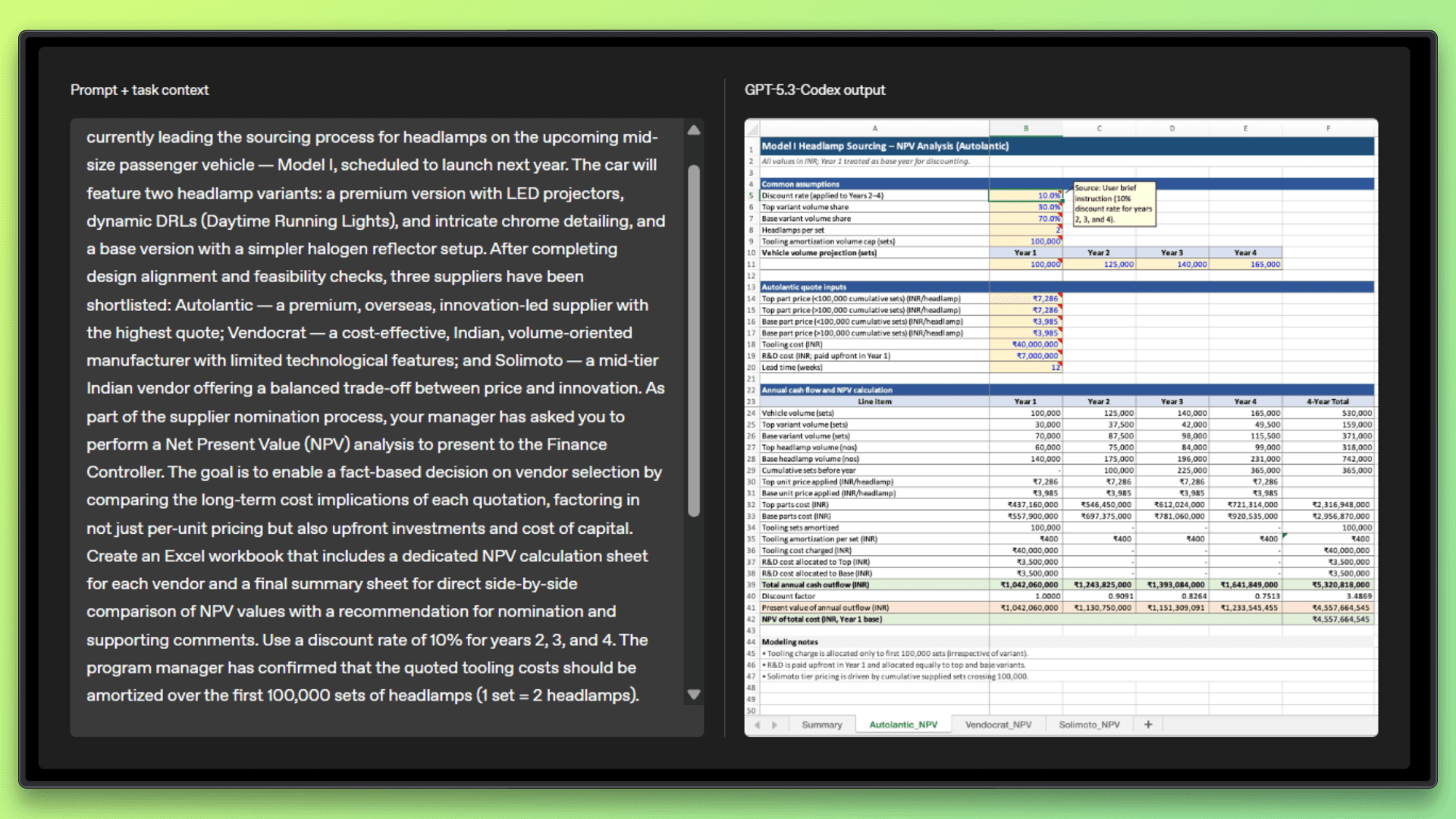
GPT 5.3 Codex can support research and data focused workflows that require sustained analysis over longer sessions. It can run experiments, aggregate results from multiple sources, and help analyze large datasets or log files to surface patterns and issues.
The model is also capable of generating structured and reproducible outputs such as reports, notebooks, or summaries that can be shared or revisited later. Because it can use tools and maintain context across longer interactions, it works well for exploratory tasks where the problem space is not fully defined upfront.
Cybersecurity Capabilities & Risk Posture
Classified as high capability for cybersecurity: GPT 5.3 Codex is the first OpenAI model that is treated as high capability in cybersecurity, which means it can handle advanced security related tasks and therefore requires stronger safeguards.
Strong performance on security benchmarks: It performs well on professional capture the flag challenges, scores around 90% on CVE Bench for identifying real-world vulnerabilities, and achieves an 80% combined pass rate on Cyber Range scenarios that simulate full attack workflows.
Capable of realistic security tasks: The model can identify vulnerabilities, explore attack surfaces, and chain multiple steps together in controlled environments, rather than solving isolated security problems.
Released with strict safety controls: Since these capabilities are dual-use, the model is deployed with layered monitoring, access controls, and safeguards to reduce misuse while still supporting legitimate defensive security work.
Codex Was Used to Train and Deploy GPT 5.3 Codex
During the development of GPT 5.3 Codex, OpenAI used early versions of Codex as an internal tool to speed up both training and deployment. Research teams relied on Codex to monitor training runs, debug issues, and analyze patterns in model behavior across different stages of training. It helped identify differences between model versions and supported deeper analysis than standard internal tools.
On the engineering side, Codex was used to optimize the deployment setup, investigate user facing edge cases, and diagnose issues such as context rendering problems and low cache hit rates. During launch, it also assisted with scaling GPU clusters to handle traffic while keeping latency stable.
In alpha testing, Codex was used to analyze session logs and measure productivity improvements, helping teams understand how the model reduced clarifications and made more progress per interaction.
GPT-5.3-Codex-Spark: A New Ultra-Fast Coding Model
GPT-5.3-Codex-Spark is a research-preview variant of OpenAI’s GPT-5.3-Codex designed specifically for interactive coding workflows. Unlike larger models that prioritize deep reasoning and comprehensive generation, Spark is optimized for real-time responsiveness, delivering rapid code suggestions, edits, and completions with minimal latency.
Powered by specialized hardware (Cerebras Wafer Scale Engine 3), the model enables developers to iterate quickly during coding sessions, especially in IDEs, command-line interfaces, and dedicated tools like Codex apps.
Spark maintains strong performance on common coding benchmarks despite being smaller than its full-size counterpart, making it ideal for tasks where speed and interactivity matter more than extensive reasoning. As a research preview, it’s being rolled out with specific rate limits and will evolve with expanded capabilities, including broader context windows and future enhancements.
Key Features of GPT 5.3 Codex Spark
Ultra-Low Latency: Built for real-time coding with extremely fast response times, enabling smooth interactive workflows.
Optimized for Live Development: Designed specifically for IDEs, CLIs, and rapid code editing scenarios.
Specialized Hardware Acceleration: Runs on Cerebras Wafer Scale Engine 3 for high-speed inference performance.
Strong Coding Performance: Delivers competitive results on coding benchmarks despite being smaller than full GPT-5.3-Codex.
128k Context Window: Supports large codebases, allowing extended code understanding within a single session.
Practical Implications for Developers
Fewer clarification loops: The model asks fewer follow-up questions and makes forward progress more consistently.
Better handling of vague prompts: Ambiguous requests result in sensible defaults instead of incomplete outputs.
More reviewing, less prompting: Developer effort shifts from crafting prompts to reviewing and guiding results.
Best fit for complex workflows: Most useful for full-stack development, infrastructure and platform work, and research-oriented tasks.
Limited gains for simple tasks: Provides less benefit for basic autocomplete or short, single-step code generation.
Final Verdict
GPT 5.3 Codex shows a clear move toward AI systems that can handle real developer work from start to finish. It is not autonomous, but it does make longer and more complex tasks easier to manage by combining reasoning, tool use, and steady execution.
It is available with paid ChatGPT plans across all Codex surfaces, including the app, CLI, IDE extension, and the web, with API access planned to roll out safely soon. The model was co-designed, trained, and deployed on NVIDIA GB200 NVL72 systems, reflecting the scale of infrastructure behind this release.
For developers working on larger codebases with Codex models, explore how Entelligence brings clarity across code review, insights, and security in modern AI led development pipelines.