



Earned Intelligence
Entelligence V3
We shipped something last month that broke our internal benchmarks. False positive rate dropped to single digits. Engineers started treating review comments like they came from a senior teammate, not a tool.
The change wasn't a better model. It wasn't more context. It was a fundamental shift in how the reviewer thinks. We taught it to argue with itself.
Every AI code reviewer in 2024 and 2025 converged on the same architecture: index the codebase, retrieve relevant context at review time, generate findings. The more context you provide, the better the reviews. That was the theory.
In practice, we observed something strange. More context often made things worse.
Tools with sophisticated retrieval would find a function that could return null, see a dereference downstream, and confidently flag a null pointer bug. Except the function was only called after validation that guaranteed non-null. The context that would disprove the finding was right there in the retrieved code. The model just didn't use it.
We saw this pattern everywhere:
The model retrieves code showing a function can throw an exception. It flags missing error handling. But the caller is wrapped in a try-catch two frames up. The context was retrieved. The reasoning was lazy.
The model sees a database query without a transaction. It flags a potential race condition. But the table has row-level locking configured. The evidence against the finding exists. The model ignored it.
The model identifies a breaking API change. It flags downstream consumers. But those consumers were already updated in the same PR. The disproof was in the diff. The model never checked.
We started calling this "context-confident hallucination." The model had everything it needed to get the right answer. It just stopped thinking too early.
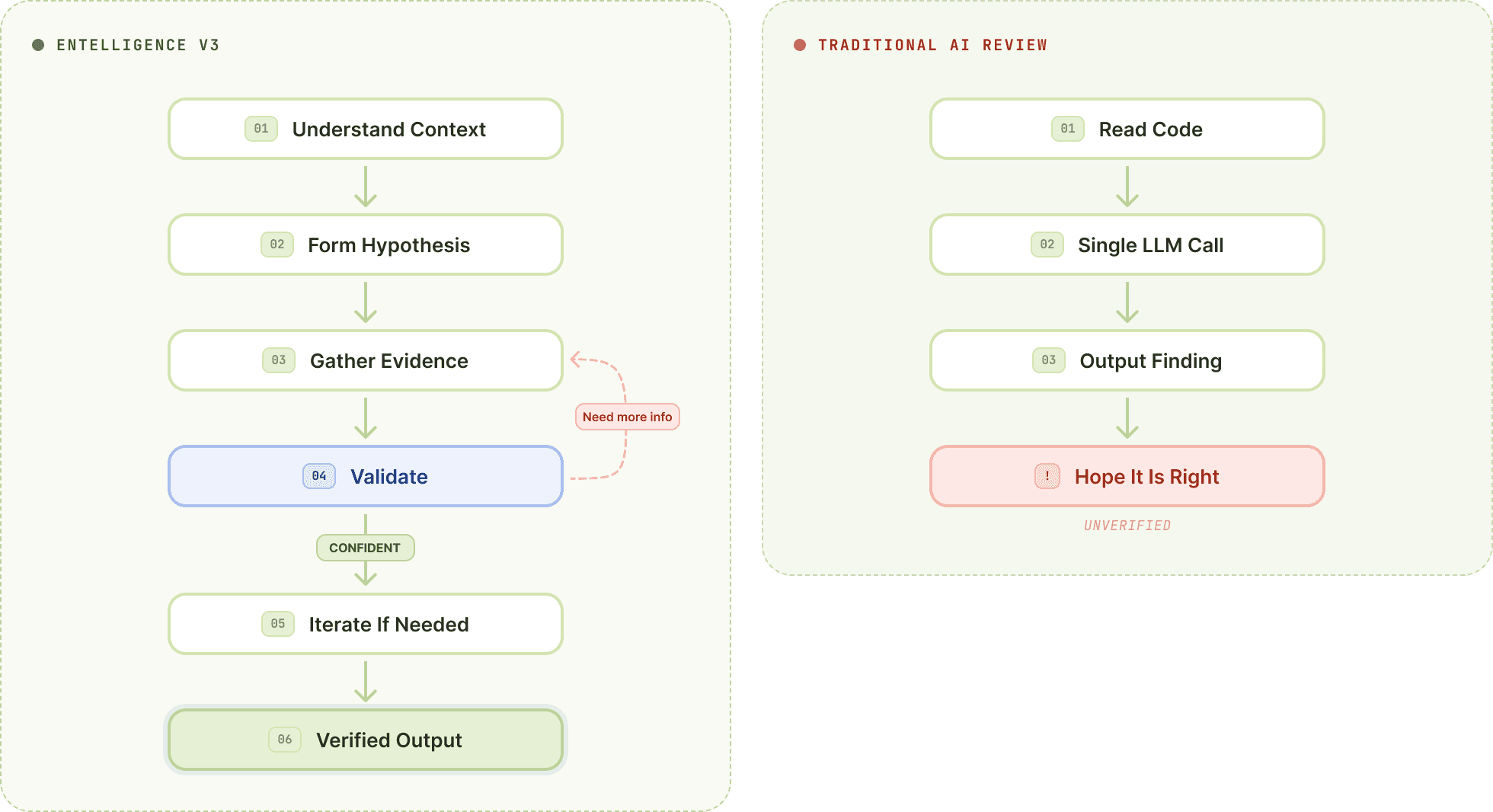
Entelligence V3 runs a loop that will feel familiar if you've used Claude Code or Codex for agentic coding. The difference is what we're optimizing for.

Agentic coding tools loop to BUILD: gather context, write code, run tests, fix errors, repeat until the code works.
We loop to DISPROVE: gather context, generate hypothesis, seek disconfirming evidence, stress-test reasoning, repeat until the finding survives or dies.
When the reviewer suspects a null pointer issue, it doesn't flag it. It asks: what would prove this wrong?
It traces upstream to find validation that guarantees non-null. It examines the call sites to see if the suspicious path is actually reachable. It checks whether similar patterns elsewhere in the codebase are intentional. It looks for tests that exercise the code path and would have caught the bug.
If it finds disconfirming evidence, the finding dies. You never see it.
If it exhausts the search and the hypothesis still holds, you get a finding with a complete evidence chain: here's the bug, here's why it's real, here's what we checked to make sure.
The loop doesn't run once. It runs until the reviewer has high confidence or has exhausted productive lines of investigation. Each iteration adds evidence. Each piece of evidence either strengthens the finding or kills it.
This is what we mean by "adversarial verification." The reviewer is trying to prove itself wrong. The findings that reach you are the ones it couldn't disprove.
You can't argue with yourself about code if you can't explore it. The verification loop needs infrastructure that can answer questions on demand: what calls this function? What validates this input? What exceptions can this path throw? How is this pattern handled elsewhere?
Most retrieval systems can't do this. They pull a fixed context window at the start and hope it contains what the model needs. If a question arises mid-reasoning that requires code not in the window, the model either hallucinates an answer or drops the thread.
The Context Engine is built for adversarial exploration.
It maintains a living semantic graph of your codebase: control flow, data flow, type relationships, call graphs, effect propagation. When the verification loop needs to check an assumption, it queries the graph directly. No hoping the right code was retrieved. No context window limits on mid-reasoning exploration.
The engine performs interprocedural analysis that tracks data across function boundaries, through async chains, across callback invocations, into closure captures. It resolves polymorphism to concrete implementations. It unwinds dependency injection to actual runtime bindings. It models nullable propagation across entire call chains and distinguishes between error paths that are theoretically possible versus actually reachable.
When the reviewer asks "is this value ever null when it reaches this dereference?" the engine doesn't retrieve files and hope. It traces the actual data flow paths and returns a definitive answer.
This is what makes the adversarial loop work. Every hypothesis the reviewer forms can be checked against the actual code. Every assumption can be validated or disproven. The reviewer explores your codebase the way a senior engineer would, pulling threads until they resolve.



Here's what nobody else does, and what became possible once we had the adversarial loop in place.
Your code doesn't exist in isolation. That API you're modifying? Other services depend on it. That shared library? Consumed across multiple repositories. Most reviewers analyze PRs in a vacuum. They catch bugs within the repo but miss breakage that crosses boundaries.
When the reviewer suspects a breaking change, it doesn't just check the current repo. It extends the adversarial loop across repos: which downstream services consume this API? Do any of them depend on the behavior being changed? Would they break, or have they already been updated?
When the reviewer suspects a breaking change, it doesn't just check the current repo. It extends the adversarial loop across repos: which downstream services consume this API? Do any of them depend on the behavior being changed? Would they break, or have they already been updated?
The same loop that kills false positives within a repo now kills false positives across repos. The reviewer tries to disprove cross-repo breakage the same way it tries to disprove any finding. What survives is real.
No more surprise breakages. No more "wait, that broke us" in Slack after deploy. You catch cross-repo impact in the PR, with evidence.
The loop has more stages than we've described. There are specific techniques for hypothesis generation, evidence weighting, confidence calibration, and termination conditions. There's a scoring system that prioritizes which threads to pull first. There's a mechanism for learning from past findings in your codebase.
We're deliberately vague about the details. This is core IP. But the principle is what matters: single-pass review will always be limited by the quality of its first inference. Adversarial verification has the entire reasoning loop to correct itself.
Enterprise codebases deserve enterprise security. Every review runs in an isolated sandbox environment. Your code is cloned, analyzed, and discarded. No persistence. No leakage. No shared state between reviews.
We never train on your code. We never store your code. We just review it.
F1 Score balances precision (avoiding noisy comments) and recall (catching real issues). It reflects how useful a review system is in real-world pull requests, not just in lab conditions.
F1 score from one of our benchmarking reports against different code reviewers:
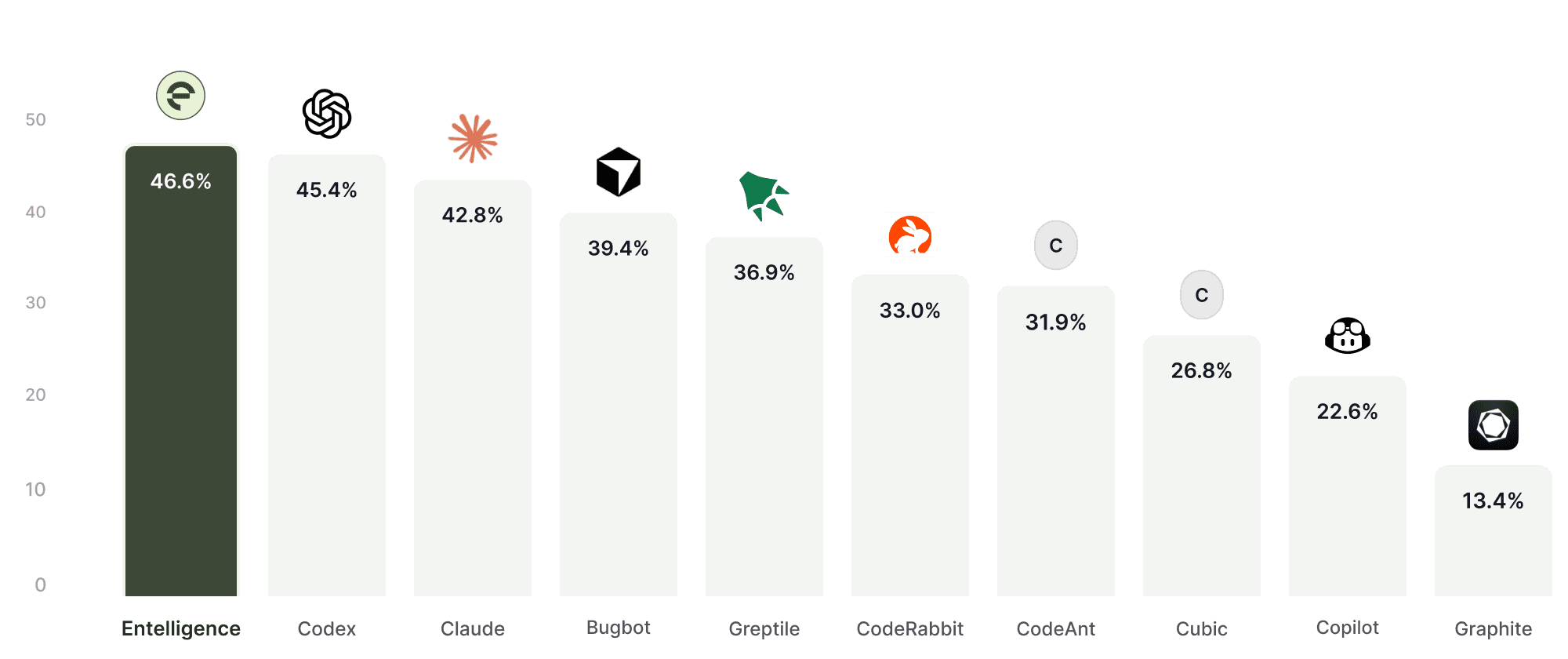
Most AI review tools optimize for one side of the equation:
High recall → Catch everything, flood the PR with comments
High precision → Avoid noise, but miss critical bugs
Neither works in production.
To measure real-world effectiveness, we benchmarked using F1 Score, which balances both.
Our V3 improvements were focused on:
Reducing redundant and low-context comments
Improving contextual understanding across files
Increasing true positive detection in configuration, infra, and security issues
The result:
Higher signal density per PR.
Fewer ignored comments.
More actionable reviews.
This is what production-grade AI review should look like.
Checkout our complete report here: Entelligence Benchmark Report 2026
More code is written with AI assistance than ever before. Copilot. Cursor. Claude. The volume requiring review keeps growing. The patterns that humans rely on to catch bugs become less reliable when the code wasn't written by humans.
Automated review has to fill that gap. But it only works if developers trust it. And trust comes from being right. Not occasionally. Consistently.
Single-pass review can't get there. It will always be limited by the quality of one inference. It will always hallucinate findings that more reasoning would have killed. It will always miss issues that deeper exploration would have found.
We built a reviewer that explores. That questions its own conclusions. That tries to prove itself wrong before it ever shows you a finding.

